重学前端
源链接:https://time.geekbang.org/column/intro/100023201 (opens new window)
# 1. 开篇词 + 学习路线 + 架构图
# 开篇词 | 从今天起,重新理解前端
keywords:软件工程体系;UI 架构;浏览器的工作原理;前端工程化;程序员通用的编程能力和架构能力。
关于前端工程师成长,需要两个视角。一是立足标准,系统性总结和整理前端知识,建立自己的认知和方法论;二是放眼团队,从业务和工程角度思考前端团队的价值和发展需要。只有这样做,才能够持续发展,在高速发展的技术和工程浪潮中稳稳立足。
# 明确你的前端学习路线与方法
keywords:前端的基础知识;前端学习方法;知识架构;前端技术背后的核心思想;基于原型的语言。
前端学习方法:【1】建立知识架构;【2】追本溯源。
文法 --> 语义 --> 运行时;对于任何计算机语言来说,必定是“用规定的文法,去表达特定语义,最终操作运行时的”一个过程。
文法:词法、语法;语义;运行时:类型、执行过程。(词法中有各种直接量、关键字、运算符,语法和语义则是表达式、语句、函数、对象、模块,类型则包含了对象、数字、字符串等……)
程序 = 算法 + 数据结构,对运行时来说,类型就是数据结构,执行过程就是算法。
JavaScript 之父 Brendan Eich 曾经在 Wikipedia 的讨论页上解释 JavaScript 最初想设计一个带有 prototype 的 scheme,结果受到管理层命令把它弄成像 Java 的样子。( 这就是为什么 javascript 最初设计成 prototype-based 而不是 class-based,链接 (opens new window))
前端基础 -> 函数库 -> 组件库 -> 框架 -> 工程化。
# 前端知识架构图
keywords:MDN。
前端的知识在总体上分成基础部分和实践部分,基础部分包含了 JavaScript 语言(模块一)、CSS 和 HTML(模块二)以及浏览器的实现原理和 API(模块三),这三个模块涵盖了一个前端工程师所需要掌握的全部知识。
# JavaScript
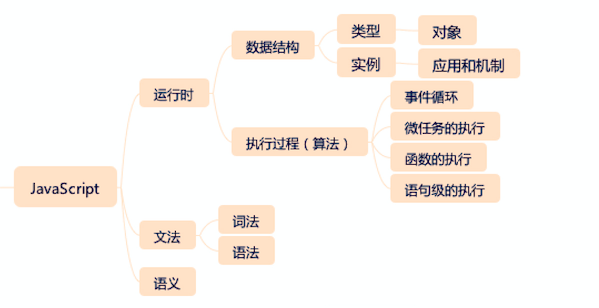
在 JavaScript 的模块中,首先我们可以把语言按照文法、语义和运行时来拆分,这符合编程语言的一般规律:用一定的词法和语法,表达一定语义,从而操作运行时。
接下来,我们又按照程序的一般规律,把运行时分为数据结构和算法部分:数据结构包含类型和实例(JavaScript 的类型系统就是它的 7 种基本类型和 7 种语言类型,实例就是它的内置对象部分)。所谓的算法,就是 JavaScript 的执行过程。
# HTML 和 CSS
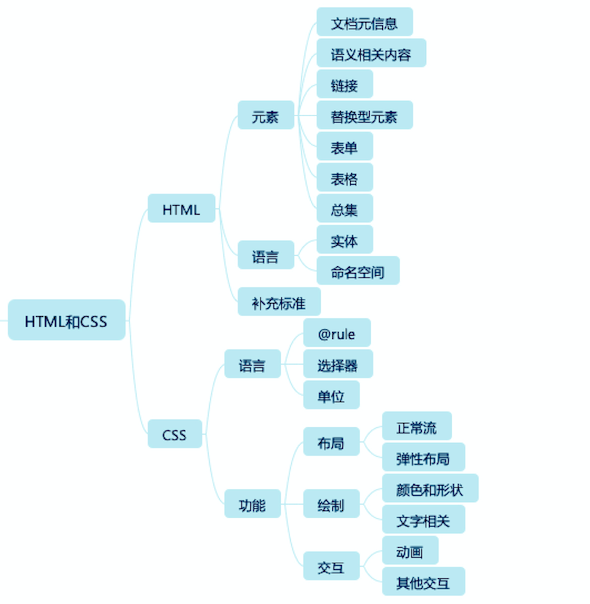
在 HTML 的部分,基于这样的分类,我把标签元素分成下面几种:
文档元信息:通常是出现在 head 标签中的元素,包含了描述文档自身的一些信息;
语义相关:扩展了纯文本,表达文章结构、不同语言要素的标签;
链接:提供到文档内和文档外的链接;
替换型标签:引入声音、图片、视频等外部元素替换自身的一类标签;
表单:用于填写和提交信息的一类标签;
表格:表头、表尾、单元格等表格的结构。
除了标签之外,我们还应该把 HTML 当作一门语言来了解下,当然,标记语言跟编程语言不太一样,没有编程语言那么严谨,所以,我们会简要介绍 HTML 的语法和几个重要的语言机制:实体、命名空间。最后我们会介绍下 HTML 的补充标准:ARIA,它是 HTML 的扩展,在可访问性领域,它有至关重要的作用。
# 浏览器的实现原理和 API
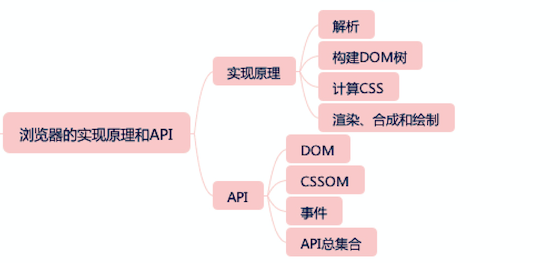
浏览器部分我们会先介绍下浏览器的实现原理,这是我们深入理解 API 的基础。会从一般的浏览器设计出发,按照解析、构建 DOM 树、计算 CSS、渲染、合成和绘制的流程来讲解浏览器的工作原理。
# 前端工程实践

性能:对任何一个前端团队而言,性能是它价值的核心指标,从早年“重构”的实践开始,前端有通过性能证明自己价值的传统。但是性能并非细节的堆砌,也不是默默做优化,所以,我会从团队的角度来跟你一起探讨性能的方法论和技术体系。
工具链:探讨企业中工具链的建设思路。对一个高效又合作良好的前端团队来说,一致性的工具链是不可或缺的保障,作为开发阶段的入口,工具链又可以和性能、发布、持续集成等系统链接到一起,成为团队技术管理的基础。
持续集成:持续集成并非一个新概念,但是过去持续集成概念和理论都主要针对软件开发,而对前端来说,持续集成是一个新的课题(当然对持续集成来说,前端也是一个新课题),比如 daily build 就完全不适用前端,前端代码必须是线上实时可用的。
搭建系统:前端工作往往多而繁杂,针对高重复性、可模块化的业务需求,传统的人工开发不再适用,搭建系统是大部分大型前端团队的选择。
架构与基础库:软件架构师主要解决功能复杂性的问题,服务端架构师主要解决高流量问题,而前端是页面间天然解耦,分散在用户端运行的系统,但是前端架构也有自己要解决的问题。前端需求量大、专业人才稀缺,更因为前端本身运行在浏览器中,有大量兼容工作要做。所以前端架构的主要职责是兼容性、复用和能力扩展。

# 2. 模块一:JavaScript
# JavaScript类型:关于类型,有哪些你不知道的细节
- 类型:JavaScript 语言的每一个值都属于某一种数据类型。JavaScript 语言规定了 7 种语言类型。语言类型广泛用于变量、函数参数、表达式、函数返回值等场合。根据最新的语言标准,这 7 种语言类型是:Undefined;Null;Boolean;String;Number;Symbol;Object。
# Undefined、Null
为什么有的编程规范要求用 void 0 代替 undefined:Undefined 类型表示未定义,它的类型只有一个值,就是 undefined。任何变量在赋值前是 Undefined 类型、值为 undefined,一般我们可以用全局变量 undefined(就是名为 undefined 的这个变量)来表达这个值,或者 void 运算来把任意一个表达式变成 undefined 值。但是呢,因为 JavaScript 的代码中 undefined 是一个变量,而并非是一个关键字,这是 JavaScript 语言公认的设计失误之一,所以为了避免无意中被篡改,建议使用 void 0 来获取 undefined 值。
Undefined 跟 Null 有一定的表意差别,Null 表示的是:“定义了但是为空”。所以,在实际编程时,我们一般不会把变量赋值为 undefined,这样可以保证所有值为 undefined 的变量,都是从未赋值的自然状态。
Null 类型也只有一个值,就是 null,它的语义表示空值,与 undefined 不同,null 是 JavaScript 关键字,所以在任何代码中,你都可以放心用 null 关键字来获取 null 值。
# Boolean
- Boolean 类型有两个值, true 和 false,它用于表示逻辑意义上的真和假,同样有关键字 true 和 false 来表示两个值。
# String
字符串是否有最大长度?String 有最大长度是 2^53 - 1,这在一般开发中都是够用的,但是有趣的是,这个所谓最大长度,并不完全是你理解中的字符数。因为 String 的意义并非“字符串”,而是字符串的 UTF16 编码,我们字符串的操作 charAt、charCodeAt、length 等方法针对的都是 UTF16 编码。所以,字符串的最大长度,实际上是受字符串的编码长度影响的。
JavaScript 中的字符串是永远无法变更的,一旦字符串构造出来,无法用任何方式改变字符串的内容,所以字符串具有值类型的特征。
JavaScript 字符串把每个 UTF16 单元当作一个字符来处理,所以处理非 BMP(超出 U+0000 - U+FFFF 范围)的字符时,你应该格外小心。【0-65536(U+0000 - U+FFFF)的码点被称为基本字符区域(BMP)】JavaScript 这个设计继承自 Java,最新标准中是这样解释的,这样设计是为了“性能和尽可能实现起来简单”。因为现实中很少用到 BMP 之外的字符。
# Number
Number 类型表示我们通常意义上的“数字”。这个数字大致对应数学中的有理数,当然,在计算机中,我们有一定的精度限制。JavaScript 中的 Number 类型有 18437736874454810627(即 2^64-2^53+3) 个值。
JavaScript 中的 Number 类型基本符合 IEEE 754-2008 规定的双精度浮点数规则,但是 JavaScript 为了表达几个额外的语言场景(比如不让除以 0 出错,而引入了无穷大的概念),规定了几个例外情况:NaN,占用了 9007199254740990,这原本是符合 IEEE 规则的数字;Infinity,无穷大;-Infinity,负无穷大。
另外,值得注意的是,JavaScript 中有 +0 和 -0,在加法类运算中它们没有区别,但是除法的场合则需要特别留意区分,“忘记检测除以 -0,而得到负无穷大”的情况经常会导致错误,而区分 +0 和 -0 的方式,正是检测 1/x 是 Infinity 还是 -Infinity。
根据双精度浮点数的定义,Number 类型中有效的整数范围是 -0x1fffffffffffff 至 0x1fffffffffffff,所以 Number 无法精确表示此范围外的整数。【支持数值范围是:-2^53~2^53,即:- 9007199254740991(0x1FFFFFFFFFFFFF)~9007199254740991(0x1FFFFFFFFFFFFF)。】
同样根据浮点数的定义,非整数的 Number 类型无法用 ==(=== 也不行) 来比较,一段著名的代码,为什么在 JavaScript 中,0.1+0.2 不能 =0.3:【非整形的数字有精度要求,所以不相等;事实上不是无法比较,浮点数是可以比较的,不过由于精度的问题可能导致一些在计算中理所当然的结果并不会出现,所以 JavaScript 才会规定浮点数不可以进行比较】
Number 类型运算都要想将其转化为二进制,将二进制运算,运算的结果再转化为十进制,因为 Number 是64位双精度,小数部分只有52位,但0.1转化成为二进制是无限循环的,所以四舍五入了,这里就发生了精度丢失,0.1的二进制和0.2的二进制相加需要保留有效数字,所以又发生了精度丢失,所以结果为0.300000000000004,所以为false,而0.2+0.3恰好两个转化成为二进制和相加的过程都不会发生精度丢失,所以为true。
console.log( 0.1 + 0.2 == 0.3);
这里输出的结果是 false,说明两边不相等的,这是浮点运算的特点,也是很多同学疑惑的来源,浮点数运算的精度问题导致等式左右的结果并不是严格相等,而是相差了个微小的值。
所以实际上,这里错误的不是结论,而是比较的方法,正确的比较方法是使用 JavaScript 提供的最小精度值;用最小精度比较,防止浮点数运算导致的精度问题造成结果错误:(检查等式左右两边差的绝对值是否小于最小精度,才是正确的比较浮点数的方法。这段代码结果就是 true 了)
console.log( Math.abs(0.1 + 0.2 - 0.3) <= Number.EPSILON);
# Symbol
Symbol 是 ES6 中引入的新类型,它是一切非字符串的对象 key 的集合,在 ES6 规范中,整个对象系统被用 Symbol 重塑。Symbol 跟对象系统的关系,在后面的文章中会详细叙述。在这里我们只介绍 Symbol 类型本身:它有哪些部分,它表示什么意思,以及如何创建 Symbol 类型。
Symbol 可以具有字符串类型的描述,但是即使描述相同,Symbol 也不相等。
我们创建 Symbol 的方式是使用全局的 Symbol 函数。例如:
var mySymbol = Symbol("my symbol");
- 一些标准中提到的 Symbol,可以在全局的 Symbol 函数的属性中找到。例如,我们可以使用 Symbol.iterator 来自定义 for…of 在对象上的行为:
var o = new Object
o[Symbol.iterator] = function() {
var v = 0
return {
next: function() {
return { value: v++, done: v > 10 }
}
}
};
for(var v of o)
console.log(v); // 0 1 2 3 ... 9
2
3
4
5
6
7
8
9
10
11
12
13
代码中我们定义了 iterator 之后,用 for(var v of o) 就可以调用这个函数,然后我们可以根据函数的行为,产生一个 for…of 的行为。这里我们给对象 o 添加了 Symbol.iterator 属性,并且按照迭代器的要求定义了一个 0 到 10 的迭代器,之后我们就可以在 for of 中愉快地使用这个 o 对象啦。
这些标准中被称为“众所周知”的 Symbol,也构成了语言的一类接口形式。它们允许编写与语言结合更紧密的 API。
# Object
Object 是 JavaScript 中最复杂的类型,也是 JavaScript 的核心机制之一。Object 表示对象的意思,它是一切有形和无形物体的总称。为什么给对象添加的方法能用在基本类型上?
在 JavaScript 中,对象的定义是“属性的集合”。属性分为数据属性和访问器属性,二者都是 key-value 结构,key 可以是字符串或者 Symbol 类型。关于对象的机制,后面会有单独的一篇来讲述,这里我重点从类型的角度来介绍对象类型。提到对象,我们必须要提到一个概念:类。因为 C++ 和 Java 的成功,在这两门语言中,每个类都是一个类型,二者几乎等同,以至于很多人常常会把 JavaScript 的“类”与类型混淆。事实上,JavaScript 中的“类”仅仅是运行时对象的一个私有属性,而 JavaScript 中是无法自定义类型的。
JavaScript 中的几个基本类型,都在对象类型中有一个“亲戚”。它们是:Number;String;Boolean;Symbol。所以,我们必须认识到 3 与 new Number(3) 是完全不同的值,它们一个是 Number 类型, 一个是对象类型。
Number、String 和 Boolean,三个构造器是两用的,当跟 new 搭配时,它们产生对象,当直接调用时,它们表示强制类型转换。Symbol 函数比较特殊,直接用 new 调用它会抛出错误,但它仍然是 Symbol 对象的构造器。
JavaScript 语言设计上试图模糊对象和基本类型之间的关系,我们日常代码可以把对象的方法在基本类型上使用,比如:
console.log("abc".charAt(0)); // a
- 甚至我们在原型上添加方法,都可以应用于基本类型,比如以下代码,在 Symbol 原型上添加了 hello 方法,在任何 Symbol 类型变量都可以调用。
Symbol.prototype.hello = () => console.log("hello");
var a = Symbol("a");
console.log(typeof a); //symbol,a并非对象
a.hello(); //hello,有效
2
3
4
5
- 所以前面的问题【为什么给对象添加的方法能用在基本类型上】,答案就是 . 运算符提供了装箱操作,它会根据基础类型构造一个临时对象,使得我们能在基础类型上调用对应对象的方法。
# 类型转换
介绍一个现象:类型转换。
因为 JavaScript 是弱类型语言,所以类型转换发生非常频繁,大部分我们熟悉的运算都会先进行类型转换。大部分类型转换符合人类的直觉,但是如果我们不去理解类型转换的严格定义,很容易造成一些代码中的判断失误。其中最为臭名昭著的是 JavaScript 中的 == 运算,因为试图实现跨类型的比较,它的规则复杂到几乎没人可以记住。这里我们当然也不打算讲解 == 的规则,它属于设计失误,并非语言中有价值的部分,很多实践中禁止使用 “==”,而使用 === 进行比较。【项目实践中,基本使用 eslint 配置一些检测规则,来规避 == 比较】
其它运算,如加减乘除大于小于,也都会涉及类型转换。幸好的是,实际上大部分类型转换规则是非常简单的,如下表所示:
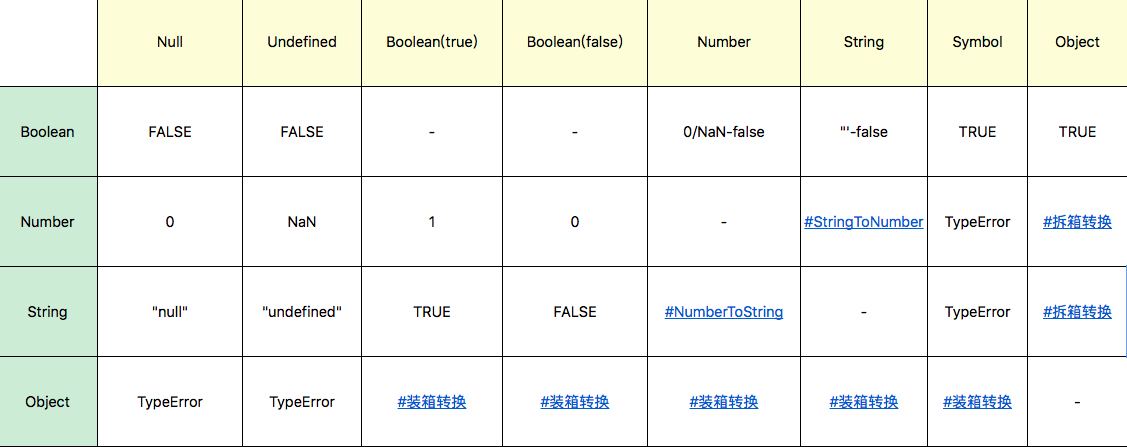
在这个里面,较为复杂的部分是 Number 和 String 之间的转换,以及对象跟基本类型之间的转换。我们分别来看一看这几种转换的规则。
StringToNumber
字符串到数字的类型转换,存在一个语法结构,类型转换支持十进制、二进制、八进制和十六进制,比如:30;0b111;0o13;0xFF。此外,JavaScript 支持的字符串语法还包括正负号科学计数法,可以使用大写或者小写的 e 来表示:1e3;-1e-2。
需要注意的是,parseInt 和 parseFloat 并不使用这个转换,所以支持的语法跟这里不尽相同。在不传入第二个参数的情况下,parseInt 只支持 16 进制前缀 “0x”,而且会忽略非数字字符,也不支持科学计数法。在一些古老的浏览器环境中,parseInt 还支持 0 开头的数字作为 8 进制前缀,这是很多错误的来源。所以在任何环境下,都建议传入 parseInt 的第二个参数,而 parseFloat 则直接把原字符串作为十进制来解析,它不会引入任何的其他进制。
多数情况下,
Number是比parseInt和parseFloat更好的选择。【Number 函数推荐使用】NumberToString
在较小的范围内,数字到字符串的转换是完全符合你直觉的十进制表示。当 Number 绝对值较大或者较小时,字符串表示则是使用科学计数法表示的。这个算法细节繁多,我们从感性的角度认识,它其实就是保证了产生的字符串不会过长。
toString方法:不能转化 underfind 和 null;String方法;num + ‘ ’。【String 函数推荐使用】装箱转换
每一种基本类型 Number、String、Boolean、Symbol 在对象中都有对应的类,所谓装箱转换,正是把基本类型转换为对应的对象,它是类型转换中一种相当重要的种类。
前文提到,全局的 Symbol 函数无法使用 new 来调用,但我们仍可以利用装箱机制来得到一个 Symbol 对象,我们可以利用一个函数的 call 方法来强迫产生装箱。我们定义一个函数,函数里面只有 return this,然后我们调用函数的 call 方法到一个 Symbol 类型的值上,这样就会产生一个 symbolObject。
我们可以用 console.log 看一下这个东西的 typeof,它的值是 object,我们使用 symbolObject instanceof 可以看到,它是 Symbol 这个类的实例,我们找它的 constructor 也是等于 Symbol 的,所以我们无论从哪个角度看,它都是 Symbol 装箱过的对象:
var symbolObject = (function(){ return this; }).call(Symbol("a")); console.log(typeof symbolObject); // object console.log(symbolObject instanceof Symbol); // true console.log(symbolObject.constructor == Symbol); // true1
2
3
4
5装箱机制会频繁产生临时对象,在一些对性能要求较高的场景下,我们应该尽量避免对基本类型做装箱转换。
使用内置的 Object 函数,我们可以在 JavaScript 代码中显式调用装箱能力。
var symbolObject = Object(Symbol("a")); console.log(typeof symbolObject); //object console.log(symbolObject instanceof Symbol); //true console.log(symbolObject.constructor == Symbol); //true1
2
3
4
5每一类装箱对象皆有私有的 Class 属性,这些属性可以用 Object.prototype.toString 获取:
var symbolObject = Object(Symbol("a")); console.log(Object.prototype.toString.call(symbolObject)); //[object Symbol]1
2
3在 JavaScript 中,没有任何方法可以更改私有的 Class 属性,因此
Object.prototype.toString是可以准确识别对象对应的基本类型的方法,它比 instanceof 更加准确。但需要注意的是,call 本身会产生装箱操作,所以需要配合 typeof 来区分基本类型还是对象类型。拆箱转换
在 JavaScript 标准中,规定了 ToPrimitive 函数,它是对象类型到基本类型的转换(即,拆箱转换)。
对象到 String 和 Number 的转换都遵循 “先拆箱再转换” 的规则。通过拆箱转换,把对象变成基本类型,再从基本类型转换为对应的 String 或者 Number。
拆箱转换会尝试调用
valueOf和toString来获得拆箱后的基本类型。如果 valueOf 和 toString 都不存在,或者没有返回基本类型,则会产生类型错误TypeError。var o = { valueOf : () => {console.log("valueOf"); return {}}, toString : () => {console.log("toString"); return {}} } o * 2 // valueOf // toString // TypeError1
2
3
4
5
6
7
8
9我们定义了一个对象 o,o 有 valueOf 和 toString 两个方法,这两个方法都返回一个对象,然后我们进行 o*2 这个运算的时候,你会看见先执行了 valueOf,接下来是 toString,最后抛出了一个 TypeError,这就说明了这个拆箱转换失败了。
到 String 的拆箱转换会优先调用 toString。我们把刚才的运算从 o*2 换成 String(o),那么你会看到调用顺序就变了。
var o = { valueOf : () => {console.log("valueOf"); return {}}, toString : () => {console.log("toString"); return {}} } String(o) // toString // valueOf // TypeError1
2
3
4
5
6
7
8
9在 ES6 之后,还允许对象通过显式指定 @@
toPrimitiveSymbol 来覆盖原有的行为。var o = { valueOf : () => {console.log("valueOf"); return {}}, toString : () => {console.log("toString"); return {}} } o[Symbol.toPrimitive] = () => {console.log("toPrimitive"); return "hello"} console.log(o + "") // toPrimitive // hello1
2
3
4
5
6
7
8
9
10
11
# 结语
在本篇文章中,我们介绍了 JavaScript 运行时的类型系统。
除了这七种语言类型,还有一些语言的实现者更关心的规范类型。
- List 和 Record: 用于描述函数传参过程。
- Set:主要用于解释字符集等。
- Completion Record:用于描述异常、跳出等语句执行过程。
- Reference:用于描述对象属性访问、delete 等。
- Property Descriptor:用于描述对象的属性。
- Lexical Environment 和 Environment Record:用于描述变量和作用域。
- Data Block:用于描述二进制数据。
有一个说法是:程序 = 算法 + 数据结构,运行时类型包含了所有 JavaScript 执行时所需要的数据结构的定义,所以我们要对它格外重视。
# 补充
- 事实上,“类型” 在 JavaScript 中是一个有争议的概念。一方面,标准中规定了运行时数据类型; 另一方面,JavaScript 语言中提供了 typeof 这样的运算,用来返回操作数的类型,但 typeof 的运算结果,与运行时类型的规定有很多不一致的地方。我们可以看下表来对照一下。
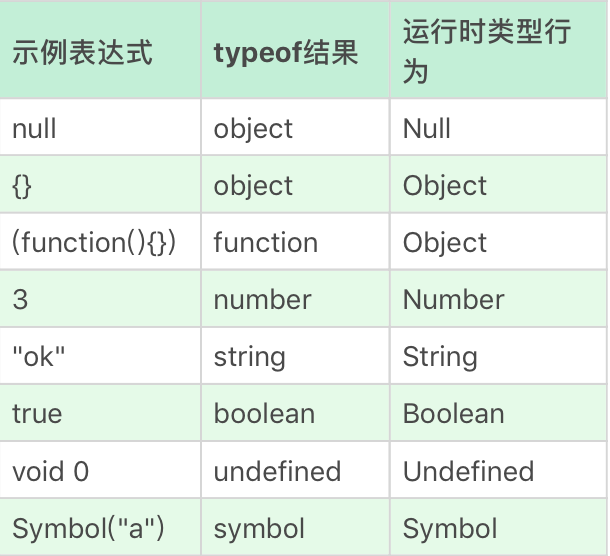
在表格中,多数项是对应的,但是请注意 object——Null 和 function——Object 是特例,我们理解类型的时候需要特别注意这个区别。从一般语言使用者的角度来看,毫无疑问,我们应该按照 typeof 的结果去理解语言的类型系统。但 JavaScript 之父本人也在多个场合表示过,typeof 的设计是有缺陷的,只是现在已经错过了修正它的时机。
不用原生的 number 和 parseInt,使用 JavaScript 实现从 string 到 number 的转换:
function strToNum(a){
let chars = a.split("").map(e => e.charCodeAt(0) - "0".charCodeAt(0));
let n = 0;
for(var char of chars){
n *= 10;
n += char;
}
return n;
}
strToNum("8947947")
2
3
4
5
6
7
8
9
10
11
# JavaScript对象:面向对象还是基于对象
- 在学习 JavaScript 面向对象时,往往也会有疑惑:为什么 JavaScript(直到 ES6)有对象的概念,但是却没有像其他的语言那样,有类的概念呢;为什么在 JavaScript 对象里可以自由添加属性,而其他的语言却不能呢。实际上,基于对象和面向对象两个形容词都出现在了 JavaScript 标准的各个版本当中。
- JavaScript 标准对基于对象的定义,这个定义的具体内容是:“语言和宿主的基础设施由对象来提供,并且 JavaScript 程序即是一系列互相通讯的对象集合”。这里的意思根本不是表达弱化的面向对象的意思,反而是表达对象对于语言的重要性。
- 什么是面向对象:【1】因为翻译的原因,中文语境下我们很难理解 “对象” 的真正含义。事实上,Object(对象)在英文中,是一切事物的总称,这和面向对象编程的抽象思维有互通之处。中文的 “对象” 却没有这样的普适性,我们在学习编程的过程中,更多是把它当作一个专业名词来理解。但不论如何,我们应该认识到,对象并不是计算机领域凭空造出来的概念,它是顺着人类思维模式产生的一种抽象(于是面向对象编程也被认为是:更接近人类思维模式的一种编程范式)。【2】在《面向对象分析与设计》这本书中,Grady Booch 替我们做了总结,他认为,从人类的认知角度来说,对象应该是下列事物之一:一个可以触摸或者可以看见的东西;人的智力可以理解的东西;可以指导思考或行动(进行想象或施加动作)的东西。【3】有了对象的自然定义后,我们就可以描述编程语言中的对象了。在不同的编程语言中,设计者也利用各种不同的语言特性来抽象描述对象,最为成功的流派是使用 “类” 的方式来描述对象,这诞生了诸如 C++、Java 等流行的编程语言。而 JavaScript 早年却选择了一个更为冷门的方式:原型,这也是说它不合群的原因之一。【4】如果我们从运行时角度来谈论对象,就是在讨论 JavaScript 实际运行中的模型,这是由于任何代码执行都必定绕不开运行时的对象模型。不过,幸运的是,从运行时的角度看,可以不必受到这些“基于类的设施”的困扰,这是因为任何语言运行时类的概念都是被弱化的。
- 在人类思维模式下,对象究竟是什么:对象这一概念在人类的幼儿期形成,这远远早于我们编程逻辑中常用的值、过程等概念。在幼年期,我们总是先认识到某一个苹果能吃(这里的某一个苹果就是一个对象),继而认识到所有的苹果都可以吃(这里的所有苹果,就是一个类),再到后来我们才能意识到三个苹果和三个梨之间的联系,进而产生数字 “3”(值)的概念。
- 类和原型是编程语言来抽象描述对象的两种不同方式。
- JavaScript 对象的特征:不论我们使用什么样的编程语言,我们都先应该去理解对象的本质特征。总结来看,对象有如下几个特点,【1】对象具有唯一标识性(内存地址):即使完全相同的两个对象,也并非同一个对象。【2】对象有状态:对象具有状态,同一对象可能处于不同状态之下。【3】对象具有行为:即对象的状态,可能因为它的行为产生变迁。
- 关于对象的第二个和第三个特征 “状态和行为”,不同语言会使用不同的术语来抽象描述它们,比如 C++ 中称它们为 “成员变量” 和 “成员函数”,Java 中则称它们为 “属性” 和 “方法”。在 JavaScript 中,将状态和行为统一抽象为 “属性”,考虑到 JavaScript 中将函数设计成一种特殊对象,所以 JavaScript 中的状态和行为都能用属性来抽象。
- 在实现了对象基本特征的基础上, 我认为,JavaScript 中对象独有的特色是:对象具有高度的动态性,这是因为 JavaScript 赋予了使用者在运行时为对象添改状态和行为的能力。为了提高抽象能力,JavaScript 的属性被设计成比别的语言更加复杂的形式,它提供了数据属性和访问器属性(getter/setter)两类。
- JavaScript 对象的两类属性:数据属性和访问器属性。对 JavaScript 来说,属性并非只是简单的名称和值,JavaScript 用一组特征(attribute)来描述属性(property)。【1】数据属性,它比较接近于其它语言的属性概念,具有四个特征。value:就是属性的值;writable:决定属性能否被赋值;enumerable:决定 for in 能否枚举该属性;configurable:决定该属性能否被删除或者改变特征值。在大多数情况下,我们只关心数据属性的值即可。【2】访问器(getter/setter)属性,它也有四个特征。getter:函数或 undefined,在取属性值时被调用;setter:函数或 undefined,在设置属性值时被调用;enumerable:决定 for in 能否枚举该属性;configurable:决定该属性能否被删除或者改变特征值。访问器属性使得属性在读和写时执行代码,它允许使用者在写和读属性时,得到完全不同的值,它可以视为一种函数的语法糖。【3】我们通常用于定义属性的代码会产生数据属性,其中的 writable、enumerable、configurable 都默认为 true。我们可以使用内置函数
getOwnPropertyDescriptor来查看。【4】如果我们要想改变属性的特征,或者定义访问器属性,我们可以使用Object.defineProperty。
var o = { a: 1 };
o.b = 2;
// a 和 b 皆为数据属性
Object.getOwnPropertyDescriptor(o,"a")
// {value: 1, writable: true, enumerable: true, configurable: true}
Object.getOwnPropertyDescriptor(o,"b")
// {value: 2, writable: true, enumerable: true, configurable: true}
2
3
4
5
6
7
var o = { a: 1 };
Object.defineProperty(o, "b", {value: 2, writable: false, enumerable: false, configurable: true});
// a 和 b 都是数据属性,但特征值变化了
Object.getOwnPropertyDescriptor(o,"a");
// {value: 1, writable: true, enumerable: true, configurable: true}
Object.getOwnPropertyDescriptor(o,"b");
// {value: 2, writable: false, enumerable: false, configurable: true}
o.b = 3;
console.log(o.b); // 2,因为 writable 特征为 false,所以我们重新对 b 赋值,b 的值不会发生变化
2
3
4
5
6
7
8
9
- 在创建对象时,也可以使用 get 和 set 关键字来创建访问器属性。访问器属性跟数据属性不同,每次访问属性都会执行 getter 或者 setter 函数。这里我们的 getter 函数返回了 1,所以 o.a 每次都得到 1。实际上 JavaScript 对象的运行时是一个 “属性的集合”,属性以字符串或者 Symbol 为 key,以数据属性特征值或者访问器属性特征值为 value。
var o = { get a() { return 1 } };
console.log(o.a); // 1
// “a”是 key
// {writable:true,value:1,configurable:true,enumerable:true}是 value
2
3
4
- 对象是一个属性的索引结构(索引结构是一类常见的数据结构,我们可以把它理解为一个能够以比较快的速度用 key 来查找 value 的字典)。
- 由于 JavaScript 的对象设计跟目前主流基于类的面向对象差异非常大。可事实上,这样的对象系统设计虽然特别,但是 JavaScript 提供了完全运行时的对象系统,这使得它可以模仿多数面向对象编程范式( JavaScript 中两种面向对象编程的范式:基于类和基于原型),所以它也是正统的面向对象语言。
- JavaScript 对象的具体设计:具有高度动态性的属性集合。
# JavaScript对象:我们真的需要模拟类吗
- JavaScript 本身就是面向对象的,只是它实现面向对象的方式和主流的流派不太一样,所以才让很多人产生了误会 -- JavaScript “模拟面向对象”,实际上做的事情就是 “模拟基于类的面向对象”。JavaScript 创始人 Brendan Eich 在 “原型运行时” 的基础上引入了 new、this 等语言特性,使之 “看起来语法更像 Java”。
- 什么是原型:原型是顺应人类自然思维的产物。中文中有个成语叫做 “照猫画虎”,这里的猫看起来就是虎的原型。【1】“基于类” 的编程提倡使用一个关注分类和类之间关系开发模型。先有类,再从类去实例化一个对象。【2】“基于原型” 的编程看起来更为提倡程序员去关注 -- 系列对象实例的行为,而后才去关心如何将这些对象,划分到最近的使用方式相似的原型对象,而不是将它们分成类。【3】基于原型的面向对象系统通过 “复制” 的方式来创建新对象。原型系统的 “复制操作” 有两种实现思路:一个是并不真的去复制一个原型对象,而是使得新对象持有一个原型的引用;另一个是切实地复制对象,从此两个对象再无关联。JavaScript 显然选择了前一种方式。
- 所有对象都有
__proto__属性, 只有函数才有prototype属性。 - JavaScript 的原型:原型系统可以说相当简单,用两条概括:如果所有对象都有私有字段
[[prototype]],就是对象的原型;读一个属性,如果对象本身没有,则会继续访问对象的原型,直到原型为空或者找到为止。 - 但从 ES6 以来,JavaScript 提供了一系列内置函数,以便更为直接地访问操纵原型。三个方法分别为:
Object.create根据指定的原型创建新对象,原型可以是 null;Object.getPrototypeOf获得一个对象的原型;Object.setPrototypeOf设置一个对象的原型。 - 早期版本中的类与原型:在早期版本的 JavaScript 中,“类” 的定义是一个
私有属性 [[class]],语言标准为内置类型诸如 Number、String、Date 等指定了 [[class]] 属性,以表示它们的类。语言使用者唯一可以访问 [[class]] 属性的方式是Object.prototype.toString。在 ES5 开始,[[class]] 私有属性被Symbol.toStringTag代替。
// 以下代码展示了所有具有内置 class 属性的对象
var o = new Object;
var n = new Number;
var s = new String;
var b = new Boolean;
var d = new Date;
var arg = function(){ return arguments }();
var r = new RegExp;
var f = new Function;
var arr = new Array;
var e = new Error;
console.log([o, n, s, b, d, arg, r, f, arr, e].map(v => Object.prototype.toString.call(v)));
[
"[object Object]",
"[object Number]",
"[object String]",
"[object Boolean]",
"[object Date]",
"[object Arguments]",
"[object RegExp]",
"[object Function]",
"[object Array]",
"[object Error]"
]
// 使用 Symbol.toStringTag 来自定义 Object.prototype.toString 的行为
var o = { [Symbol.toStringTag]: "MyObject" }
console.log(o + ""); // [object MyObject]
// 这里创建了一个新对象,并且给它唯一的一个属性 Symbol.toStringTag,我们用字符串加法触发了 Object.prototype.toString 的调用,发现这个属性最终对 Object.prototype.toString 的结果产生了影响
var o = {
[Symbol.toStringTag]: "MyObject",
toString() {
console.log("重写toString");
return "abc";
}
}
console.log(o + "");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
- JavaScript 语法中 new 操作具体做了哪些事情:要把 new 理解成 JavaScript 面向对象的一部分。new 运算接受一个构造器和一组调用参数,实际上做了几件事:以构造器的 prototype 属性(注意与私有字段 [[prototype]] 的区分)为原型,创建新对象;将 this 和调用参数传给构造器,执行;如果构造器返回的是对象,则返回,否则返回第一步创建的对象。new 这样的行为,试图让函数对象在语法上跟类变得相似,但是,它客观上提供了两种方式,一是在构造器中添加属性,二是在构造器的 prototype 属性上添加属性。
// 下面代码展示了用构造器模拟类的两种方法
// 1、直接在构造器中修改 this,给 this 添加属性
function c1 () {
this.p1 = 1;
this.p2 = function () {
console.log(this.p1);
}
}
var o1 = new c1;
o1.p2();
// 2、修改构造器的 prototype 属性指向的对象
function c2 () {
}
c2.prototype.p1 = 1;
c2.prototype.p2 = function () {
console.log(this.p1);
}
var o2 = new c2;
o2.p2();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// Object.create 的不完整的 polyfill(一个是不支持第二个参数,另一个是不支持 null 作为原型)
Object.create = function(prototype){
var cls = function(){}
cls.prototype = prototype;
return new cls;
}
2
3
4
5
6
- ES6 中的类:好在 ES6 中加入了新特性 class,new 跟 function 搭配的怪异行为终于可以退休了(虽然运行时没有改变),在任何场景,我都推荐使用 ES6 的语法来定义类,而令 function 回归原本的函数语义。ES6 中引入了 class 关键字,并且在标准中删除了所有[[class]]相关的私有属性描述,类的概念正式从属性升级成语言的基础设施。类提供了继承能力。
// 类的基本写法
class Animal {
// 数据型成员最好写在构造器里面
constructor(name) {
this.name = name;
}
speak() {
console.log(this.name + ' makes a noise.');
}
}
class Dog extends Animal {
constructor(name) {
super(name); // call the super class constructor and pass in the name parameter
}
speak() {
console.log(this.name + ' barks.');
}
}
let d = new Dog('Mitzie');
d.speak(); // Mitzie barks.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# JavaScript对象:你知道全部的对象分类吗
- JavaScript 的对象机制并非简单的属性集合 + 原型。
- JavaScript 中的对象分类:【1】宿主对象(host Objects):由 JavaScript 宿主环境提供的对象,它们的行为完全由宿主环境决定。【2】内置对象(Built-in Objects):由 JavaScript 语言提供的对象。固有对象(Intrinsic Objects ):由标准规定,随着 JavaScript 运行时创建而自动创建的对象实例。原生对象(Native Objects):可以由用户通过 Array、RegExp 等内置构造器或者特殊语法创建的对象。普通对象(Ordinary Objects):由 {} 语法、Object 构造器或者 class 关键字定义类创建的对象,它能够被原型继承。
- 宿主对象:前端最熟悉的无疑是浏览器环境中的宿主,window 对象。
- 内置对象:【1】固有对象:在任何 JavaScript 代码执行前就已经被创建出来了,它们通常扮演着类似基础库的角色。ECMA 标准为我们提供了一份固有对象表,里面含有 150+ 个固有对象。你可以通过这个链接 (opens new window)查看。【2】原生对象:JavaScript 标准中,提供了 30 多个构造器。通过这些构造器,用 new 运算创建新的对象,所以我们把这些对象称作原生对象。几乎所有这些构造器的能力都是无法用纯 JavaScript 代码实现的,它们也无法用 class/extend 语法来继承。
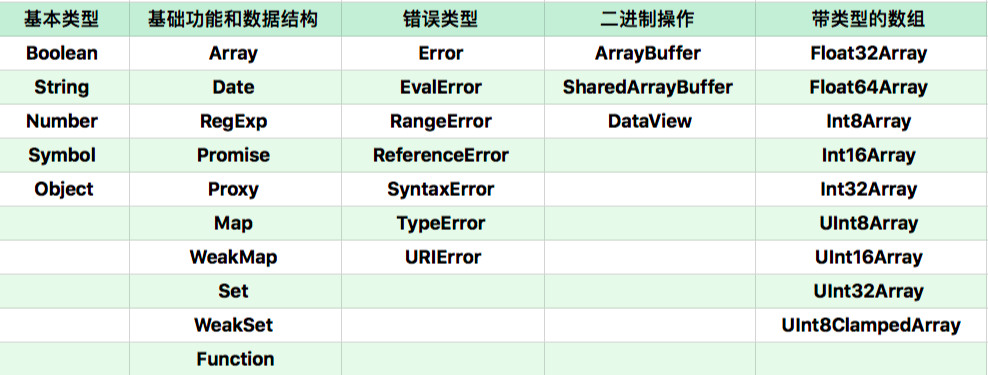
// 构造器创建的对象多数使用了私有字段
// 这些字段使得原型继承方法无法正常工作,所有这些原生对象都是为了特定能力或者性能,而设计出来的“特权对象”
Error: [[ErrorData]]
Boolean: [[BooleanData]]
Number: [[NumberData]]
Date: [[DateValue]]
RegExp: [[RegExpMatcher]]
Symbol: [[SymbolData]]
Map: [[MapData]]
2
3
4
5
6
7
8
9
- 用对象来模拟函数与构造器:函数对象与构造器对象。在 JavaScript 中,还有一个看待对象的不同视角,这就是用对象来模拟函数和构造器。事实上,JavaScript 为这一类对象预留了私有字段机制。函数对象的定义是:具有
[[call]]私有字段的对象,构造器对象的定义是:具有私有字段[[construct]]的对象。对于宿主和内置对象来说,它们实现[[call]](作为函数被调用)和[[construct]](作为构造器被调用)不总是一致的。
// 内置对象 Date 在作为构造器调用时产生新的对象,作为函数时则产生字符串
typeof new Date // 'object'
typeof Date() // 'string'
// 浏览器宿主环境中,提供的 Image 构造器,则根本不允许被作为函数调用
typeof new Image // 'object'
Image() // 抛出错误
// 基本类型(String、Number、Boolean),它们的构造器被当作函数调用,则产生类型转换的效果
// 在 ES6 之后 => 语法创建的函数仅仅是函数,它们无法被当作构造器使用
new (a => 0) // error
// 对于用户使用 function 语法或者 Function 构造器创建的对象来说,[[call]]和[[construct]]行为总是相似的,它们执行同一段代码
function f(){
return 1;
}
var v = f(); // 把 f 作为函数调用
var o = new f(); // 把 f 作为构造器调用
// [[construct]] 的执行过程
// 以 Object.prototype 为原型创建一个新对象;以新对象为 this,执行函数的 [[call]];如果 [[call]] 的返回值是对象,那么,返回这个对象,否则返回第一步创建的新对象。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 特殊行为的对象:在固有对象和原生对象中它们常见的下标运算(就是使用中括号或者点来做属性访问)或者设置原型跟普通对象不同,这里简单总结一下:【1】Array:Array 的 length 属性根据最大的下标自动发生变化。【2】Object.prototype:作为所有正常对象的默认原型,不能再给它设置原型了。【3】String:为了支持下标运算,String 的正整数属性访问会去字符串里查找。【4】Arguments:arguments 的非负整数型下标属性跟对应的变量联动。【5】模块的 namespace 对象:特殊的地方非常多,跟一般对象完全不一样,尽量只用于 import 吧。【6】类型数组和数组缓冲区:跟内存块相关联,下标运算比较特殊。【7】bind 后的 function:跟原来的函数相关联。
- 获取全部 JavaScript 固有对象:从 JavaScript 标准中可以找到全部的 JavaScript 对象定义。JavaScript 语言规定了全局对象的属性。【1】三个值:
Infinity、NaN、undefined。【2】九个函数:eval、isFinite、isNaN、parseFloat、parseInt、decodeURI、decodeURIComponent、encodeURI、encodeURIComponent。【3】一些构造器:Array、Date、RegExp、Promise、Proxy、Map、WeakMap、Set、WeakSet、Function、Boolean、String、Number、Symbol、Object、Error、EvalError、RangeError、ReferenceError、SyntaxError、TypeError、URIError、ArrayBuffer、SharedArrayBuffer、DataView、Typed Array、Float32Array、Float64Array、Int8Array、Int16Array、Int32Array、UInt8Array、UInt16Array、UInt32Array、UInt8ClampedArray。【4】四个用于当作命名空间的对象:Atomics、JSON、Math、Reflect。
// 使用广度优先搜索,查找这些对象所有的属性和 Getter/Setter
var set = new Set();
var objects = [
eval,
isFinite,
isNaN,
parseFloat,
parseInt,
decodeURI,
decodeURIComponent,
encodeURI,
encodeURIComponent,
Array,
Date,
RegExp,
Promise,
Proxy,
Map,
WeakMap,
Set,
WeakSet,
Function,
Boolean,
String,
Number,
Symbol,
Object,
Error,
EvalError,
RangeError,
ReferenceError,
SyntaxError,
TypeError,
URIError,
ArrayBuffer,
SharedArrayBuffer,
DataView,
Float32Array,
Float64Array,
Int8Array,
Int16Array,
Int32Array,
Uint8Array,
Uint16Array,
Uint32Array,
Uint8ClampedArray,
Atomics,
JSON,
Math,
Reflect];
objects.forEach(o => set.add(o));
for(var i = 0; i < objects.length; i++) {
var o = objects[i]
for(var p of Object.getOwnPropertyNames(o)) {
var d = Object.getOwnPropertyDescriptor(o, p)
if( (d.value !== null && typeof d.value === "object") || (typeof d.value === "function"))
if(!set.has(d.value))
set.add(d.value), objects.push(d.value);
if( d.get )
if(!set.has(d.get))
set.add(d.get), objects.push(d.get);
if( d.set )
if(!set.has(d.set))
set.add(d.set), objects.push(d.set);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# JavaScript执行(一):Promise里的代码为什么比setTimeout先执行
- 我们首先应该形成一个感性的认知:一个 JavaScript 引擎会常驻于内存中,它等待着我们(宿主)把 JavaScript 代码或者函数传递给它执行。
- 在 ES3 和更早的版本中,JavaScript 本身还没有异步执行代码的能力,这也就意味着,宿主环境传递给 JavaScript 引擎一段代码,引擎就把代码直接顺次执行了,这个任务也就是宿主发起的任务。但是,在 ES5 之后,JavaScript 引入了 Promise,这样,不需要浏览器的安排,JavaScript 引擎本身也可以发起任务了。
- 由于我们这里主要讲 JavaScript 语言,那么采纳 JSC 引擎(参考 (opens new window))的术语,我们把宿主发起的任务称为宏观任务,把 JavaScript 引擎发起的任务称为微观任务。
- 宏观和微观任务:JavaScript 引擎等待宿主环境分配宏观任务,在操作系统中,通常等待的行为都是一个事件循环,所以在 Node 术语中,也会把这个部分称为事件循环。【1】在宏观任务中,JavaScript 的 Promise 还会产生异步代码,JavaScript 必须保证这些异步代码在一个宏观任务中完成,因此,每个宏观任务中又包含了一个微观任务队列。【2】有了宏观任务和微观任务机制,我们就可以实现 JavaScript 引擎级和宿主级的任务了,例如:Promise 永远在队列尾部添加微观任务。setTimeout 等宿主 API,则会添加宏观任务。
// 事件循环的原理
// 在底层的 C/C++ 代码中,这个事件循环是一个跑在独立线程中的循环,我们用伪代码来表示
while(TRUE) {
r = wait();
execute(r);
}
// 整个循环做的事情基本上就是反复“等待 - 执行”
// 这里每次的执行过程,其实都是一个宏观任务。我们可以大概理解:宏观任务的队列就相当于事件循环。
2
3
4
5
6
7
8
- Promise:Promise 是 JavaScript 语言提供的一种标准化的异步管理方式,它的总体思想是,需要进行 io、等待或者其它异步操作的函数,不返回真实结果,而返回一个“承诺”,函数的调用方可以在合适的时机,选择等待这个承诺兑现(通过 Promise 的 then 方法的回调)。
// Promise 的基本用法
function sleep(duration) {
return new Promise(function(resolve, reject) {
setTimeout(resolve,duration);
})
}
sleep(1000).then( ()=> console.log("finished"))
2
3
4
5
6
7
总结一下如何分析异步执行的顺序:首先我们分析有多少个宏任务;在每个宏任务中,分析有多少个微任务;根据调用次序,确定宏任务中的微任务执行次序;根据宏任务的触发规则和调用次序,确定宏任务的执行次序;确定整个顺序。
新特性
async/await:async/await 是 ES2016 新加入的特性,它提供了用 for、if 等代码结构来编写异步的方式。它的运行时基础是 Promise。async 函数必定返回 Promise,我们把所有返回 Promise 的函数都可以认为是异步函数。async 函数是一种特殊语法,特征是在 function 关键字之前加上 async 关键字,这样,就定义了一个 async 函数,我们可以在其中使用 await 来等待一个 Promise。generator/iterator也常常被跟异步一起来讲,我们必须说明 generator/iterator 并非异步代码,只是在缺少 async/await 的时候,一些框架(最著名的要数 co)使用这样的特性来模拟 async/await。但是 generator 并非被设计成实现异步,所以有了 async/await 之后,generator/iterator 来模拟异步的方法应该被废弃。小练习:实现一个红绿灯,把一个圆形 div 按照绿色 3 秒,黄色 1 秒,红色 2 秒循环改变背景色。
function sleep(duration){
return new Promise(function(resolve){
setTimeout(resolve, duration);
})
}
async function changeColor(duration,color){
document.getElementById("traffic-light").style.background = color;
await sleep(duration);
}
async function main(){
while(true){
await changeColor(3000, "green");
await changeColor(1000, "yellow");
await changeColor(2000, "red");
}
}
main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# JavaScript执行(二):闭包和执行上下文到底是怎么回事
- 主要内容:闭包;作用域链;执行上下文;this 值。尽管它们是表示不同的意思的术语,所指向的几乎是同一部分知识,那就是函数执行过程相关的知识。
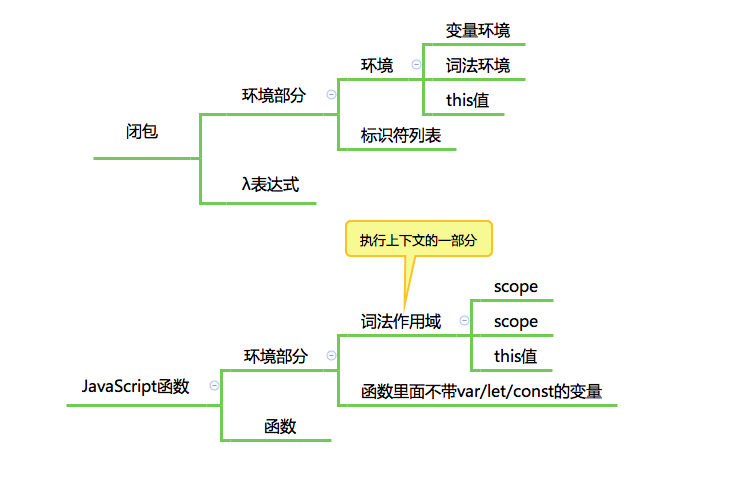
- 闭包:翻译自英文单词 closure,这是个不太好翻译的词,在计算机领域,它就有三个完全不相同的意义:编译原理中,它是处理语法产生式的一个步骤;计算几何中,它表示包裹平面点集的凸多边形(翻译作凸包);而在编程语言领域,它表示一种函数。我们可以这样简单理解一下,闭包其实只是一个绑定了执行环境的函数,这个函数并不是印在书本里的一条简单的表达式,闭包与普通函数的区别是,它携带了执行的环境,就像人在外星中需要自带吸氧的装备一样,这个函数也带有在程序中生存的环境。【1】古典的闭包定义中,闭包包含两个部分:环境部分(环境、标识符列表);表达式部分。【2】根据古典定义,在 JavaScript 中找到对应的闭包组成部分:环境部分(环境:函数的词法环境(执行上下文的一部分)、标识符列表:函数中用到的未声明的变量);表达式部分:函数体。
- 闭包主要用来解决局部变量无法长期保存(函数运行结束函数作用域就被销毁了)。
- 执行上下文:执行的基础设施。相比普通函数,JavaScript 函数的主要复杂性来自于它携带的 “环境部分”。JavaScript 标准把一段代码(包括函数),执行所需的所有信息定义为:“执行上下文”。
1、执行上下文在 ES3 中,包含三个部分:
● scope:作用域,也常常被叫做作用域链;
● variable object:变量对象,用于存储变量的对象;
● this value:this 值。
2、执行上下文在 ES5 中,最初的三个部分改进了命名方式:
● lexical environment:词法环境,当获取变量时使用;
● variable environment:变量环境,当声明变量时使用;
● this value:this 值。
3、在 ES2018 中,执行上下文又变成了这个样子,this 值被归入 lexical environment:
● lexical environment:词法环境,当获取变量或者 this 值时使用;
● variable environment:变量环境,当声明变量时使用;
● code evaluation state:用于恢复代码执行位置;
● Function:执行的任务是函数时使用,表示正在被执行的函数;
● ScriptOrModule:执行的任务是脚本或者模块时使用,表示正在被执行的代码;
● Realm:使用的基础库和内置对象实例;
● Generator:仅生成器上下文有这个属性,表示当前生成器。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 从代码实例出发,推导函数执行过程中需要哪些信息,它们又对应着执行上下文中的哪些部分:
var b = {};
let c = 1;
this.a = 2;
// var 把 b 声明到哪里;
// b 表示哪个变量;
// b 的原型是哪个对象;
// let 把 c 声明到哪里;
// this 指向哪个对象。
2
3
4
5
6
7
8
- var 声明与赋值:分析一段代码,
var b = 1。通常我们认为它声明了 b,并且为它赋值为 1,var 声明作用域是函数执行的作用域。也就是说,var 会穿透 for 、if 等语句。【1】在只有 var,没有 let 的旧 JavaScript 时代,诞生了一个技巧,叫做:立即执行的函数表达式(IIFE),通过创建一个函数,并且立即执行,来构造一个新的域,从而控制 var 的范围。【2】由于语法规定了 function 关键字开头是函数声明,所以要想让函数变成函数表达式,我们必须得加点东西,最常见的做法是加括号。【3】立即执行函数的更好的写法:void function(){}()。语义上 void 运算表示忽略后面表达式的值,直接变成 undefined,我们确实不关心 IIFE 的返回值,所以语义也更为合理。
(function(){
var a;
//code
}());
(function(){
var a;
//code
})();
// 但是,括号有个缺点,那就是如果上一行代码不写分号,括号会被解释为上一行代码最末的函数调用,产生完全不符合预期,并且难以调试的行为,加号等运算符也有类似的问题。
// 所以一些推荐不加分号的代码风格规范,会要求在括号前面加上分号。
;(function(){
var a;
//code
}())
;(function(){
var a;
//code
})()
// 我比较推荐的写法是使用 void 关键字,立即执行函数的更好的写法
void function(){
var a;
//code
}();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// 有时候 var 的特性会导致声明的变量和被赋值的变量是两个 b,使用 with 的时候
var b;
void function(){
var env = {b:1};
b = 2;
console.log("In function b:", b);
with(env) {
var b = 3;
console.log("In with b:", b);
}
}();
console.log("Global b:", b);
2
3
4
5
6
7
8
9
10
11
12
- let:是 ES6 开始引入的新的变量声明模式,比起 var 的诸多弊病,let 做了非常明确的梳理和规定。为了实现 let,JavaScript 在运行时引入了块级作用域。在 let 出现之前,JavaScript 的 if、for 等语句皆不产生作用域。以下语句会产生 let 使用的作用域:
for;if;switch;try/catch/finally。 - Realm:在最新的标准(9.0)中,JavaScript 引入了一个新概念 Realm,它的中文意思是“国度”“领域”“范围”。看这段代码:
var b = {},在 ES2016 之前的版本中,标准中甚少提及{}的原型问题。但在实际的前端开发中,通过 iframe 等方式创建多 window 环境并非罕见的操作,所以,这才促成了新概念 Realm 的引入。Realm 中包含一组完整的内置对象,而且是复制关系。【Realm 可以理解为 JavaScript 的命名空间,虽然每个里面的固定数据类型是一样的,但是不在同一个空间里,镜像一样】
// 在浏览器环境中获取来自两个 Realm 的对象
// 它们跟本土的 Object 做 instanceOf 时会产生差异
var iframe = document.createElement('iframe');
document.documentElement.appendChild(iframe);
iframe.src="javascript:var b = {};";
var b1 = iframe.contentWindow.b;
var b2 = {};
console.log(b1 instanceof Object, b2 instanceof Object); // false true
// 由于 b1、 b2 由同样的代码“ {} ”在不同的 Realm 中执行,所以表现出了不同的行为。
2
3
4
5
6
7
8
9
10
11
var b = 10;
(function b(){
b = 20;
console.log(b); // [Function: b]
})();
// 这个地方比较特殊,"具有名称的函数表达式"会在外层词法环境和它自己执行产生的词法环境之间产生一个词法环境,再把自己的名称和值当作变量塞进去,所以这里的b = 20 并没有改变外面的b,而是试图改变一个只读的变量b。
// 在同一个作用域内,同名函数会覆盖变量;同名变量会被忽略。
2
3
4
5
6
7
# JavaScript执行(三):你知道现在有多少种函数吗以及this关键字
- 在 JavaScript,切换上下文最主要的场景是函数调用。
- 函数:在 ES2018 中,函数已经是一个很复杂的体系。【1】第一种,普通函数:用 function 关键字定义的函数。【2】第二种,箭头函数:用 => 运算符定义的函数。【3】第三种,方法:在 class 中定义的函数。
class C { foo() { // code } }。【4】第四种,生成器函数:用 function * 定义的函数。【5】第五种,类:用 class 定义的类,实际上也是函数。【6】异步函数:普通函数、箭头函数和生成器函数加上 async 关键字。(都是遵循了 “继承定义时环境” 的规则,它们的行为差异在于 this 关键字) - this 关键字的行为:this 是 JavaScript 中的一个关键字,它的使用方法类似于一个变量(但是 this 跟变量的行为有很多不同)。this 是执行上下文中很重要的一个组成部分,同一个函数调用方式不同,得到的 this 值也不同。普通函数的 this 值由 “调用它所使用的引用” 决定,其中奥秘就在于:我们获取函数的表达式,它实际上返回的并非函数本身,而是一个 Reference 类型。【1】Reference 类型由两部分组成:一个对象和一个属性值。【2】调用函数时使用的引用,决定了函数执行时刻的 this 值。【3】箭头函数,不论用什么引用来调用它,都不影响它的 this 值。【4】es6 中类和模块的内部,默认就是严格模式,所以不需要使用
use strict指定运行模式。在严格模式和非严格模式下函数中的 this 值会有不同,类默认为严格模式,函数在进入执行环境时没有设置 this 的值,this 会保持为 undefined。
function showThis () {
console.log(this);
}
var o = {
showThis: showThis
}
showThis(); // global
o.showThis(); // o
// o.showThis 产生的 Reference 类型,即由对象 o 和属性 “showThis” 构成
class C {
showThis() {
console.log(this);
}
}
var o = new C();
var showThis = o.showThis;
showThis(); // undefined
o.showThis(); // o
// 方法的行为跟普通函数有差异,恰恰是因为 class 设计成了默认按 strict 模式执行。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- this 关键字的机制:在 JavaScript 标准中,为函数规定了用来保存定义时上下文的私有属性
[[Environment]]。当一个函数执行时,会创建一条新的执行环境记录,记录的外层词法环境(outer lexical environment)会被设置成函数的[[Environment]]。这个动作就是切换上下文。【1】this 是一个更为复杂的机制,JavaScript 标准定义了[[thisMode]]私有属性。有三个取值:lexical,表示从上下文中找 this,这对应了箭头函数;global,表示当 this 为 undefined 时,取全局对象,对应了普通函数;strict,当严格模式时使用,this 严格按照调用时传入的值,可能为 null 或者 undefined。 - 操作 this 的内置函数:
Function.prototype.call和Function.prototype.apply可以指定函数调用时传入的 this 值。Function.prototype.bind它可以生成一个绑定过的函数。call、bind 和 apply 作用于不接受 this 的函数类型时如箭头、class 都不会报错,它们无法实现改变 this 的能力,但是可以实现传参。 - 仅普通函数和类能够跟 new 搭配使用。
# JavaScript执行(四):try里面放return,finally还会执行吗
- 语句是任何编程语言的基础结构。比较常见的语句包括变量声明、表达式、条件、循环等。
- 小实验:finally 中的内容必须保证执行,所以 try/catch 执行完毕,即使得到的结果是非 normal 型的完成记录,也必须要执行 finally。而当 finally 执行也得到了非 normal 记录,则会使 finally 中的记录作为整个 try 结构的结果。
function foo () {
try {
return 0;
} catch (err) {
} finally {
console.log("a")
}
}
console.log(foo()); // a 0
function foo () {
try {
return 0;
} catch (err) {
} finally {
return 1;
}
}
console.log(foo()); // 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- Completion 类型:JavaScript 语句执行的完成状态,我们用一个标准类型来表示:
Completion Record,用于描述异常、跳出等语句执行过程。表示一个语句执行完之后的结果,它有三个字段:[[type]]表示完成的类型,有 break continue return throw 和 normal 几种类型;[[value]]表示语句的返回值,如果语句没有,则是 empty;[[target]]表示语句的目标,通常是一个 JavaScript 标签(标签在后文会有介绍)。语句有几种分类:
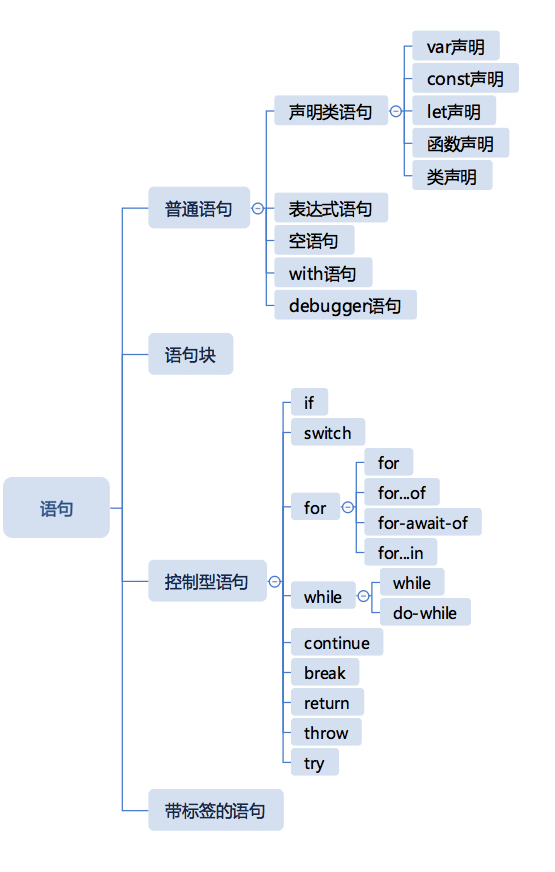
- 普通的语句:把不带控制能力的语句称为普通语句。普通语句执行后,会得到 [[type]] 为 normal 的 Completion Record,JavaScript 引擎遇到这样的 Completion Record,会继续执行下一条语句。
- 语句块:就是拿大括号括起来的一组语句,它是一种语句的复合结构,可以嵌套。
- 控制型语句:会对不同类型的 Completion Record 产生反应。控制类语句分成两部分,一类是对其内部造成影响,如 if、switch、while/for、try;另一类是对外部造成影响如 break、continue、return、throw,这两类语句的配合,会产生控制代码执行顺序和执行逻辑的效果,这也是我们编程的主要工作。
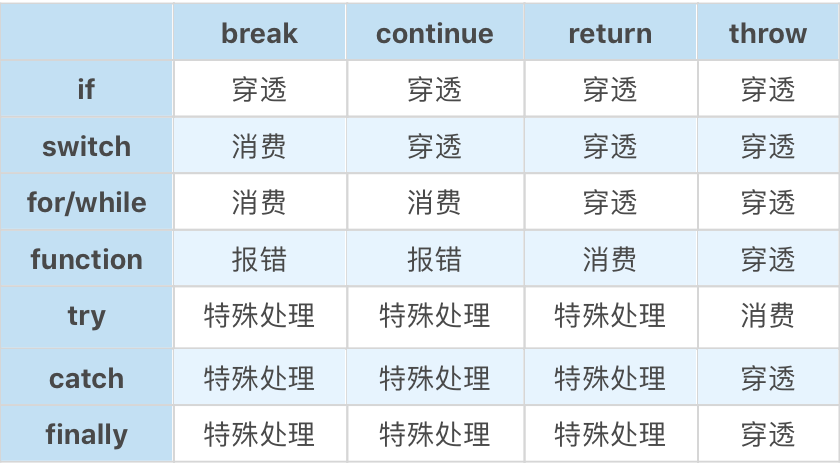
- 带标签的语句:是 JavaScript 中的一个语法。大部分时候,这个东西类似于注释,没有任何用处。唯一有作用的时候是,与完成记录类型中的 target 相配合,用于跳出多层循环。
// 任何 JavaScript 语句是可以加标签的,在语句前加冒号即可
firstStatement: var i = 1;
outer: while(true) {
inner: while(true) {
break outer;
}
}
console.log("finished")
2
3
4
5
6
7
8
9
# JavaScript词法:为什么12.toString会报错
- 文法是编译原理中对语言的写法的一种规定,一般来说,文法分成词法和语法两种。词法规定了语言的最小语义单元:token,可以翻译成 “标记” 或者 “词”。
- 词法概述:以下这个设计符合比较通用的编程语言设计方式。也有一些特别之处:【1】首先是除法和正则表达式冲突问题。对词法分析来说,其实是没有办法处理的,所以 JavaScript 的解决方案是定义两组词法,然后靠语法分析传一个标志给词法分析器,让它来决定使用哪一套词法。【2】另一个特别设计是字符串模板。理论上,
“ ${ } ”内部可以放任何 JavaScript 表达式代码,而这些代码是以“ } ”结尾的,也就是说,这部分词法不允许出现“ } ”运算符。【3】要实现 JavaScript 的解释器,词法分析和语法分析非常麻烦,需要来回传递信息。
先来看一看 JavaScript 的词法定义,JavaScript 源代码中的输入可以这样分类:
1、WhiteSpace 空白字符
2、LineTerminator 换行符
3、Comment 注释
4、Token 词:
● IdentifierName 标识符名称,典型案例是我们使用的变量名,注意这里关键字也包含在内了。
● Punctuator 符号,我们使用的运算符和大括号等符号。
● NumericLiteral 数字直接量,就是我们写的数字。
● StringLiteral 字符串直接量,就是我们用单引号或者双引号引起来的直接量。
● Template 字符串模板,用反引号 ` 括起来的直接量。
是否允许 “}” 的两种情况,与除法和正则表达式的两种情况相乘就是四种词法定义,所以在 JavaScript 标准中,可以看到四种定义:
● InputElementDiv;
● InputElementRegExp;
● InputElementRegExp;
● InputElementTemplateTail。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 空白符号 Whitespace:印象中就是空格,但是实际上,JavaScript 可以支持更多空白符号。【1】U+0009,是缩进 TAB 符,也就是字符串中写的 \t。【2】U+0020,就是最普通的空格。【3】U+00A0,非断行空格,多数的 JavaScript 编辑环境都会把它当做普通空格,HTML 中的
& nbsp;最后生成的就是它了。【4】U+FEFF,这是 ES5 新加入的空白符,是 Unicode 中的零宽非断行空格。 - 换行符 LineTerminator:JavaScript 中只提供了 4 种字符作为换行符,【1】
<LF>U+000A,就是最正常换行符,在字符串中的\n。【2】<CR>U+000D,这个字符真正意义上的 “回车”,在字符串中是\r,在一部分 Windows 风格文本编辑器中,换行是两个字符\r\n。【3】<LS>U+2028,是 Unicode 中的行分隔符。【4】<PS>U+2029,是 Unicode 中的段落分隔符。大部分 LineTerminator 在被词法分析器扫描出之后,会被语法分析器丢弃,但是换行符会影响 JavaScript 的两个重要语法特性:自动插入分号和“no line terminator”规则。 - 注释 Comment:分为单行注释和多行注释两种。
/* MultiLineCommentChars */
// SingleLineCommentChars
2
- 标识符名称 IdentifierName:可以以美元符 “$”、下划线 “_” 或者 Unicode 字母开始,除了开始字符以外,IdentifierName 中还可以使用 Unicode 中的连接标记、数字、以及连接符号。IdentifierName 的任意字符可以使用 JavaScript 的 Unicode 转义写法。
// 注意和是 ES5 新加入的两个格式控制字符,它们都是 0 宽的。
// 关键字也属于这个部分,在 JavaScript 中,关键字有:
await break case catch class const continue debugger default delete do else export extends finally for function if import instanceof new return super switch this throw try typeof var void while with yield
// 除了上述的内容之外,还有 1 个为了未来使用而保留的关键字:
enum
// 在严格模式下, 有一些额外的为未来使用而保留的关键字:
implements package protected interface private public
2
3
4
5
6
7
8
- 符号 Punctuator:所有符号为:
{ ( ) [ ] . ... ; , < > <= >= == != === !== + - * % ** ++ -- << >> >>> & | ^ ! ~ && || ? : = += -= *= %= **= <<= >>= >>>= &= |= ^= => / /= }
- 数字直接量 NumericLiteral:JavaScript 规范中规定的数字直接量可以支持四种写法,十进制数、二进制整数、八进制整数和十六进制整数。
// 十进制的 Number 可以带小数,小数点前后部分都可以省略,但是不能同时省略
.01
12.
12.01
// 这都是合法的数字直接量。这里就有一个问题,也是我们标题提出的问题
// 需要写成:12..toString() 或 12 .toString() 就没事
12.toString() // Uncaught SyntaxError: Invalid or unexpected token
// 数字直接量还支持科学计数法
10.24E+2
10.24e-2
10.24e2
// 当以0x 0b 或者0o 开头时,表示特定进制的整数 16 / 2 / 8
0xFA
0o73
0b10000
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 字符串直接量 StringLiteral:支持单引号和双引号两种写法。
- 正则表达式直接量 RegularExpressionLiteral:正则表达式由 Body 和 Flags 两部分组成,例如,
/RegularExpressionBody/g。【1】正则表达式有自己的语法规则,在词法阶段,仅会对它做简单解析。【2】正则表达式并非机械地见到 / 就停止,在正则表达式 [ ] 中的 / 就会被认为是普通字符。【3】除了 \、/ 和 [ 三个字符之外,JavaScript 正则表达式中的字符都是普通字符。 - 字符串模板 Template:从语法结构上,Template 是个整体,其中的
${ }是并列关系。但是实际上,在 JavaScript 词法中,包含 ${ } 的 Template,是被拆开分析的。
`a${b}c${d}e`
// 被拆开分析:
模板头: `a${
普通标识符:b
模板中段: }c${
普通标识符:d
模板尾: }e`
2
3
4
5
6
7
// 模板支持添加处理函数的写法,这时模板的各段会被拆开,传递给函数当参数:
function f(){
console.log(arguments);
}
var a = "world"
f`Hello ${a}!`; // [["Hello ", "!"], world]
2
3
4
5
6
- 零宽空格和零宽连接符、零宽非连接符:有妙用,如隐形水印、加密信息分享和逃脱关键词匹配。
# (小实验)理解编译原理:一个四则运算的解释器
- 分析:按照编译原理相关的知识,这里分成几个步骤,【1】定义四则运算:产出四则运算的词法定义和语法定义。【2】词法分析:把输入的字符串流变成 token。【3】语法分析:把 token 变成抽象语法树 AST。【4】解释执行:后序遍历 AST,执行得出结果。
- 定义四则运算:四则运算就是加减乘除四种运算。首先我们来定义词法,四则运算里面只有数字和运算符;接下来我们来定义语法,语法定义多数采用
BNF;语法定义的核心思想不会变,都是几种结构的组合产生一个新的结构,所以语法定义也叫语法产生式。 - 词法分析:词法分析有两种方案,一种是状态机,一种是正则表达式,它们是等效的。
- 语法分析:LL 语法分析根据每一个产生式来写一个函数。实际上一般编译代码都应该支持流式处理。
- 解释执行:得到了 AST 之后,最困难的一步我们已经解决了。接下来,直接进入执行阶段,我们只需要对这个树做遍历操作执行即可。根据不同的节点类型和其它信息,写 if 分别处理即可。
# JavaScript语法(预备篇):到底要不要写分号呢
- 语言风格问题:究竟要不要写分号。实际上,行尾使用分号的风格来自于 Java,也来自于 C 语言和 C++,这一设计最初是为了降低编译器的工作负担。
- 自动插入分号规则:独立于所有的语法产生式定义,它的规则说起来非常简单,只有三条。要有换行符,且下一个符号是不符合语法的,那么就尝试插入分号;有换行符,且语法中规定此处不能有换行符,那么就自动插入分号;源代码结束处,不能形成完整的脚本或者模块结构,那么就自动插入分号。
no LineTerminator here规则:表示它所在的结构中的这一位置不能插入换行符。
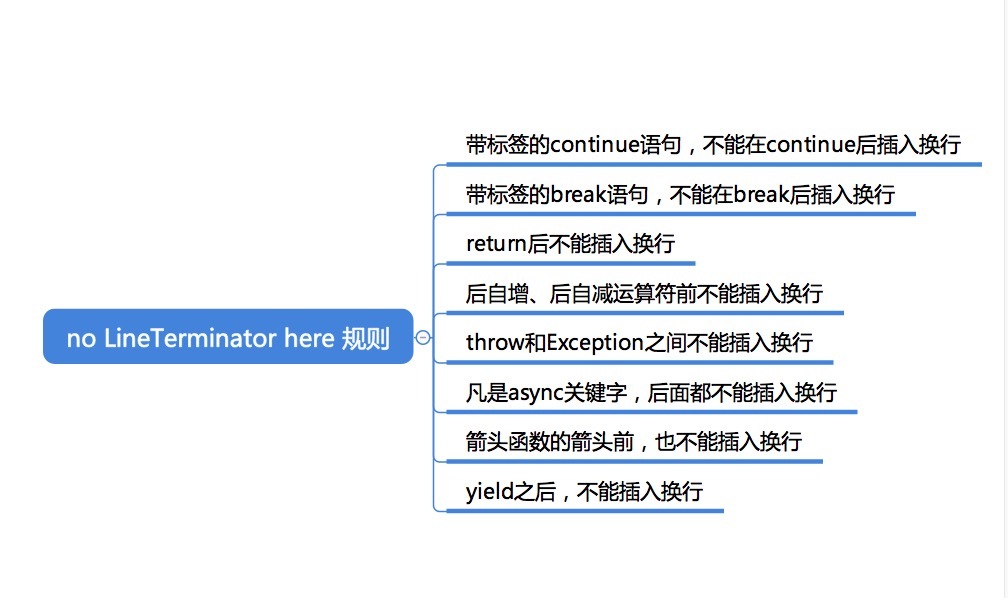
- 不写分号容易造成错误的情况:以括号开头的语句;以数组开头的语句;以正则表达式开头的语句;以 Template 开头的语句。
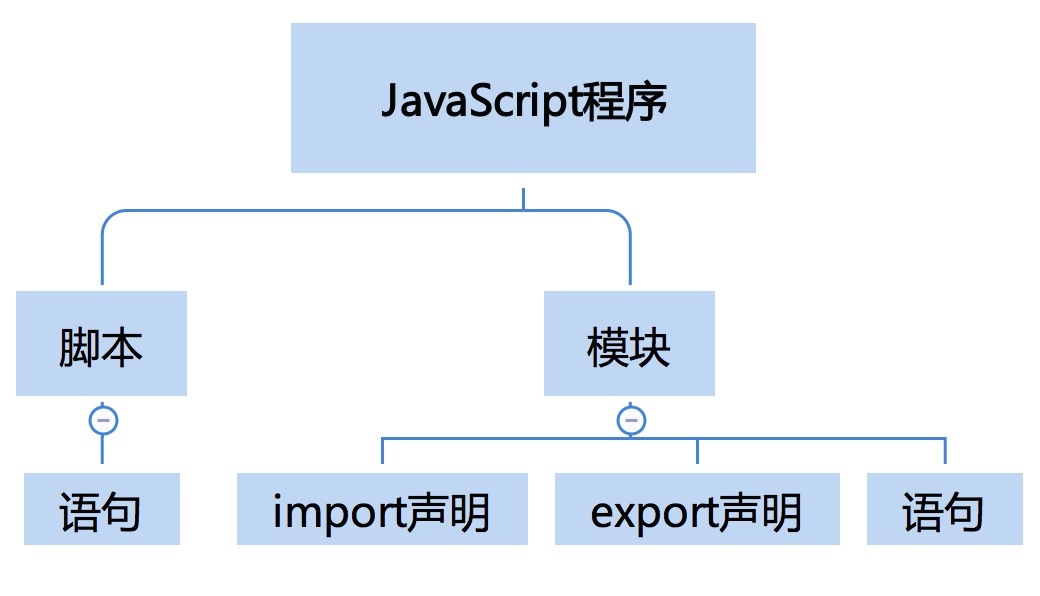
# JavaScript语法(一):在script标签写export为什么会抛错
- 脚本和模块:JavaScript 有两种源文件,一种叫做脚本,一种叫做模块。这个区分是在 ES6 引入了模块机制开始的,在 ES5 和之前的版本中,就只有一种源文件类型(就只有脚本)。【1】脚本是可以由浏览器或者 node 环境引入执行的,而模块只能由 JavaScript 代码用 import 引入执行。【2】从概念上,我们可以认为脚本具有主动性的 JavaScript 代码段,是控制宿主完成一定任务的代码;而模块是被动性的 JavaScript 代码段,是等待被调用的库。【3】现代浏览器支持用 script 标签引入模块或者脚本,如果要引入模块,必须给 script 标签添加
type=“module”。如果引入脚本,则不需要 type。【4】script 标签如果不加 type=“module”,默认认为我们加载的文件是脚本而非模块,如果我们在脚本中写了 export,当然会抛错。
<script type="module" src="xxxxx.js"></script>
- import 声明:有两种用法,一个是直接 import 一个模块(只是保证了这个模块代码被执行);另一个是带 from 的 import,它能引入模块里的一些信息,可以把它们变成本地的变量。
import "mod"; // 引入一个模块
import v from "mod"; // 把模块默认的导出值放入变量v
2
- export 声明:承担的是导出的任务。模块中导出变量的方式有两种,一种是独立使用 export 声明,另一种是直接在声明型语句前添加 export 关键字。export 还有一种特殊的用法,就是跟 default 联合使用。export default 表示导出一个默认变量值。
// 独立使用 export 声明就是一个 export 关键字加上变量名列表,例如:
export { a, b, c };
// 这里的行为跟导出变量是不一致的,这里导出的是值,导出的就是普通变量 a 的值,以后 a 的变化与导出的值就无关了,修改变量 a,不会使得其他模块中引入的 default 值发生改变
// export导出的是变量的引用(浅拷贝),但是 export default 表达式导出的是变量的值(深拷贝)
var a = {};
export default a;
// 在 import 语句前无法加入 export,但是我们可以直接使用 export from 语法
export a from "a.js"
2
3
4
5
6
7
8
9
10
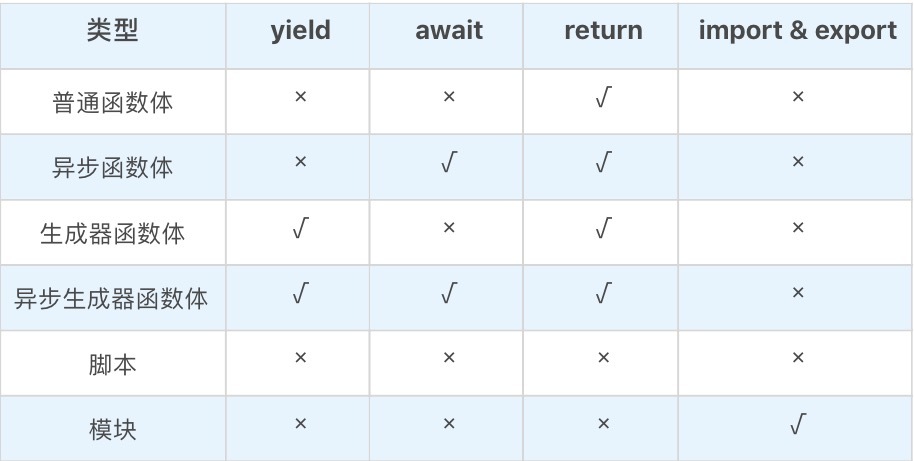
- 函数体:宏任务中可能会执行的代码包括 “脚本 (script)”、“模块(module)” 和 “函数体(function body)”。函数体其实也是一个语句的列表,跟脚本和模块比起来,函数体中的语句列表中多了 return 语句可以用。函数体实际上有四种,普通函数体、异步函数体、生成器函数体、异步生成器函数体(区别在于,能否使用 await 或者 yield 语句)。
// 异步生成器函数体
async function *foo () {
// Function body
}
2
3
4
- 两个 JavaScript 语法的全局机制:预处理和指令序言。(指令序言 --> 严格模式)
- 预处理:JavaScript 执行前,会对脚本、模块和函数体中的语句进行预处理。预处理过程将会提前处理 var、函数声明、class、const 和 let 这些语句,以确定其中变量的意义。【1】var 声明永远作用于脚本、模块和函数体这个级别。var 除了脚本和函数体都会穿透,人民群众发明了 “立即执行的函数表达式(IIFE)”这一用法,用来产生作用域。
// 预处理过程在执行之前,所以有函数体级的变量 a,就不会去访问外层作用域中的变量 a 了,而函数体级的变量 a 此时还没有赋值,所以是 undefined
var a = 1;
function foo () {
console.log(a);
var a = 2;
}
foo(); // undefined
// var 的作用能够穿透一切语句结构,它只认脚本、模块和函数体三种语法结构
var a = 1;
function foo() {
console.log(a);
if(false) {
var a = 2;
}
}
foo(); // undefined
// 预处理处理了 var,那时候的作用域是函数体级别的;而程序运行到 with 的时候,a 被对象的属性劫持了
var a = 1;
function foo () {
var o = { a: 3 }
with (o) {
var a = 2;
}
console.log(o.a); // 2
console.log(a); // undefined
}
foo();
// IIFE
for(var i = 0; i < 20; i ++) {
void function(i){
var div = document.createElement("div");
div.innerHTML = i;
div.onclick = function(){
console.log(i);
}
document.body.appendChild(div);
}(i);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
- function 声明:function 声明的行为原本跟 var 非常相似,但是在最新的 JavaScript 标准中,对它进行了一定的修改。在全局(脚本、模块和函数体),function 声明表现跟 var 相似,不同之处在于,function 声明不但在作用域中加入变量,还会给它赋值。
console.log(foo); // f
function foo(){
}
console.log(foo); // f / node --> undefined
if(true) {
function foo(){
}
}
2
3
4
5
6
7
8
9
10
11
- class 声明:class 声明在全局的行为跟 function 和 var 都不一样。【1】class 声明也是会被预处理的,它会在作用域中创建变量,并且要求访问它时抛出错误。【2】class 的声明作用不会穿透 if 等语句结构,所以只有写在全局环境才会有声明作用。
- 指令序言机制:脚本和模块都支持一种特别的语法,叫做指令序言(Directive Prologs)。【1】
"use strict"是 JavaScript 标准中规定的唯一一种指令序言, 如果"use strict"没有出现在最前,就不是指令序言。但是设计指令序言的目的是,留给 JavaScript 的引擎和实现者一些统一的表达方式,在静态扫描时指定 JavaScript 代码的一些特性。【2】JavaScript 的指令序言是只有一个字符串直接量的表达式语句,它只能出现在脚本、模块和函数体的最前面。
# JavaScript语法(二):你知道哪些JavaScript语句
- 在 JavaScript 标准中,把语句分成了两种:普通语句和声明型语句。
- 语句块:就是一对大括号。语句块会产生作用域。
- 空语句:就是一个独立的分号,实际上没什么大用。
;就这。 - if 语句:条件语句,if 语句的作用是,在满足条件时执行它的内容语句,这个语句可以是一个语句块。
- switch 语句:继承自 Java,Java 中的 switch 语句继承自 C 和 C++,原本 switch 语句是跳转的变形,所以我们如果要用它来实现分支,必须要加上 break。
- 循环语句:【1】while 循环和 do while 循环。【2】普通 for 循环。【3】for in 循环:循环枚举对象的属性,这里体现了属性的 enumerable 特征。【4】for of 循环和 for await of 循环:for of 循环是非常棒的语法特性,但是实际上,它背后的机制是 iterator 机制。
- return:用于函数中,它终止函数的执行,并且指定函数的返回值。
- break 语句和 continue 语句:break 语句用于跳出循环语句或者 switch 语句,continue 语句用于结束本次循环并继续循环。这两个语句都属于控制型语句。
- with 语句:with 语句是个非常巧妙的设计,但它把 JavaScript 的变量引用关系变得不可分析,所以一般都认为这种语句都属于糟粕。with 语句把对象的属性在它内部的作用域内变成变量。
- try 语句和 throw 语句:用于处理异常。【1】try 部分用于标识捕获异常的代码段,catch 部分则用于捕获异常后做一些处理,而 finally 则是用于执行后做一些必须执行的清理工作。【2】一般来说,throw 用于抛出异常,但是单纯从语言的角度,我们可以抛出任何值,也不一定是异常逻辑,但是为了保证语义清晰,不建议用 throw 表达任何非异常逻辑。
- debugger 语句:通知调试器在此断点。
- 以上都是普通语句,下面的是声明型语句。声明型语句跟普通语句最大区别就是声明型语句响应预处理过程,普通语句只有执行过程。
- var:是古典的 JavaScript 中声明变量的方式。
- let 和 const:新设计的语法,所以没有什么硬伤,非常地符合直觉。let 和 const 的作用范围是 if、for 等结构型语句。let 和 const 语句在重复声明时会抛错,这能够有效地避免变量名无意中冲突。
- class 声明:最基本的用法只需要 class 关键字、名称和一对大括号。它的声明特征跟 const 和 let 类似,都是作用于块级作用域,预处理阶段则会屏蔽外部变量。
const a = 2;
if(true){
console.log(a); //抛错
class a {
}
}
2
3
4
5
6
7
- 函数声明:使用 function 关键字。
# JavaScript语法(三):什么是表达式语句
- 什么是表达式语句:实际上就是一个表达式,它是由运算符连接变量或者直接量构成的。一般来说,我们的表达式语句要么是函数调用,要么是赋值,要么是自增、自减。下面就来了解下都有哪些表达式,我们从粒度最小到粒度最大了解一下。
- PrimaryExpression 主要表达式:表达式的原子项,是表达式的最小单位,它所涉及的语法结构也是优先级最高的。包含了各种 “直接量”,直接量就是直接用某种语法写出来的具有特定类型的值。【1】Primary Expression 还可以是 this 或者变量,在语法上,把变量称作 “标识符引用”。【2】任何表达式加上圆括号,都被认为是 Primary Expression,这个机制使得圆括号成为改变运算优先顺序的手段。
this;
myVar;
(a + b);
2
3
4
- MemberExpression 成员表达式:通常是用于访问对象成员的,最初设计是为了属性访问的。它有几种形式:【1】
new.target是个新加入的语法,用于判断函数是否是被 new 调用。【2】super 则是构造函数中,用于访问父类的属性的语法。
a.b;
a["b"];
new.target; // 是一个整体
super.b;
2
3
4
- NewExpression NEW 表达式:这种非常简单,Member Expression 加上 new 就是 New Expression(当然,不加 new 也可以构成 New Expression,JavaScript 中默认独立的高优先级表达式都可以构成低优先级表达式)。
// 稍微复杂的例子:
new new Cls(1);
// 等价于:
new (new Cls(1));
// 可以用以下代码来验证:
class Cls{
constructor(n){
console.log("cls", n);
return class {
constructor(n) {
console.log("returned", n);
}
}
}
}
new (new Cls(1));
// cls 1
// returned undefined
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- CallExpression 函数调用表达式:除了 New Expression,Member Expression 还能构成 Call Expression。它的基本形式是 Member Expression 后加一个括号里的参数列表,或者我们可以用上 super 关键字代替 Member Expression。
a.b(c);
super();
// 一些变体,比如:
a.b(c)(d)(e);
a.b(c)[3];
a.b(c).d;
a.b(c)`xyz`;
2
3
4
5
6
7
8
- LeftHandSideExpression 左值表达式:New Expression 和 Call Expression 统称 LeftHandSideExpression,左值表达式,就是可以放到等号左边的表达式。
- AssignmentExpression 赋值表达式:也有多种形态,最基本的当然是使用等号赋值:
a = b
// 这个等号是可以嵌套的:
a = b = c = d
// 这样的连续赋值,是右结合的,它等价于下面这种:
a = (b = (c = d))
// 赋值表达式的使用,还可以结合一些运算符,例如:
a += b; // a = a + b;
// *=、/=、%=、+=、-=、<<=、>>=、>>>=、&=、^=、|=、**=
2
3
4
5
6
7
8
9
- Expression 表达式:在 JavaScript 中,表达式就是用逗号运算符连接的赋值表达式。比赋值运算优先级更低的就是逗号运算符了,可以把逗号可以理解为一种小型的分号。
a = b, b = 1, null;
// 逗号分隔的表达式会顺次执行,就像不同的表达式语句一样。
// “整个表达式的结果” 就是 “最后一个逗号后的表达式结果”。 --> null
2
3
# JavaScript语法(四):新加入的**运算符,哪里有些不一样呢
- 在一些通用的计算机语言设计理论中,能够出现在赋值表达式右边的叫做:右值表达式(RightHandSideExpression),而在 JavaScript 标准中,规定了在等号右边表达式叫做条件表达式(ConditionalExpression),不过,在 JavaScript 标准中,从未出现过右值表达式字样。JavaScript 标准也规定了左值表达式同时都是条件表达式(也就是右值表达式)。
- 更新表达式 UpdateExpression:左值表达式搭配
++ --运算符,可以形成更新表达式。在 ES2018 中,跟早期版本有所不同,前后自增自减运算被放到了同一优先级。 - 一元运算表达式 UnaryExpression:更新表达式搭配一元运算符,可以形成一元运算表达式。
delete a.b;
void a;
typeof a;
- a;
~ a;
! a;
await a;
// 它的特点就是一个更新表达式搭配了一个一元运算符。
2
3
4
5
6
7
8
- 乘方表达式 ExponentiationExpression:乘方表达式也是由更新表达式构成的,它使用
**号。**运算是右结合。4 ** 3 ** 2 --> 4 ** (3 ** 2)。 - 乘法表达式 MultiplicativeExpression:乘方表达式可以构成乘法表达式,用乘号或者除号、取余符号连接就可以了。
x * 2;。 - 加法表达式 AdditiveExpression:加法表达式是由乘法表达式用加号或者减号连接构成的。
a + b * c。不过要注意,加号还能表示字符串连接。 - 移位表达式 ShiftExpression:移位表达式由加法表达式构成,移位是一种位运算。移位运算把操作数看做二进制表示的整数,然后移动特定位数。所以左移 n 位相当于乘以 2 的 n 次方,右移 n 位相当于除以 2 取整 n 次。(在 JavaScript 中,二进制操作整数并不能提高性能,移位运算这里也仅仅作为一种数学运算存在,这些运算存在的意义也仅仅是照顾 C 系语言用户的习惯了)
<< 向左移位
>> 向右移位
>>> 无符号向右移位
// 普通移位会保持正负数。无符号移位会把减号视为符号位 1,同时参与移位:
-1 >>> 1 // 2147483647
2
3
4
5
6
- 关系表达式 RelationalExpression:移位表达式可以构成关系表达式,这里的关系表达式就是大于、小于、大于等于、小于等于等运算符号连接,统称为关系运算。
<= >= < > instanceof in。需要注意,这里的 <= 和 >= 关系运算,完全是针对数字的。 - 相等表达式 EqualityExpression:相等表达式是由关系表达式用相等比较运算符(如 ==)连接构成的。
== != === !==。包含一个 JavaScript 中著名的设计失误,那就是 == 的行为。 - 位运算表达式:把操作数视为二进制整数,然后把两个操作数按位做与 / 异或 / 或运算。按位与表达式 BitwiseANDExpression(&)、按位异或表达式 BitwiseANDExpression(^,两位相同时得 0,两位不同时得 1)、按位或表达式 BitwiseORExpression(|)。
- 逻辑与表达式和逻辑或表达式:逻辑表达式具有短路的特性。
- 条件表达式 ConditionalExpression:又称三目运算符,它有三个部分,由两个运算符
?和:配合使用。
# 3. 模块二:HTML和CSS
# HTML语义:div和span不是够用了吗
- 语义类标签是什么,使用它有什么好处:在很多工作场景里,语义类标签也有它们自己无可替代的优点,正确地使用语义标签可以带来很多好处。【1】语义类标签对开发者更为友好,使用语义类标签增强了可读性,也更为便于团队的开发和维护。【2】除了对人类友好之外,语义类标签也十分适宜机器阅读,更适合搜索引擎检索(SEO)。
- 错误地使用语义标签,会给机器阅读造成混淆、增加嵌套,给 CSS 编写加重负担。
- 作为自然语言延伸的语义类标签:【1】使用的第一个场景,也是最自然的使用场景,就是作为自然语言和纯文本的补充,用来表达一定的结构或者消除歧义。(在 HTML5 中,就引入了这个表示
ruby的标签,它由 ruby、rt、rp 三个标签来实现)【2】还有一种情况是,HTML 的有些标签实际上就是必要的,甚至必要的程度可以达到:如果没有这个标签,文字会产生歧义的程度。(em标签) - 作为标题摘要的语义类标签:中国古代小说就形成了 “章 - 回” 的概念,西方的戏剧也有幕的区分,所以人类的自然语言作品也是如出一辙。从 HTML 5 开始,我们有了
section标签,这个标签可不仅仅是一个 “有语义的 div”,它会改变 h1-h6 的语义,section 的嵌套会使得其中的 h1-h6 下降一级。 - 作为适合机器阅读的整体结构的语义类标签:我们想介绍的最后一个场景是,随着越来越多的浏览器推出 “阅读模式”,以及各种非浏览器终端的出现,语义化的 HTML 适合机器阅读的特性变得越来越重要。应用了语义化结构的页面,可以明确地提示出页面信息的主次关系,它能让浏览器很好地支持 “阅读视图功能”,还可以让搜索引擎的命中率提升,同时,它也对视障用户的读屏软件更友好。
# HTML语义:如何运用语义类标签来呈现Wiki网页
- Wikipedia 文章,这种跟论文相似的网站比较适合用来学习语义类标签。通过分析一篇 Wiki 的文章用到的语义类标签,来进一步帮你理解语义的概念。https://en.wikipedia.org/wiki/World_Wide_Web (opens new window),副本:http://static001.geekbang.org/static/time/quote/World_Wide_Web-Wikipedia.html (opens new window)。
- 语义标签:用对 > 不用 > 用错。可以参考 Apple (中国大陆) (opens new window)。
# HTML元信息类标签:你知道head里一共能写哪几种标签吗
- 元信息类标签:所谓元信息,是指描述自身的信息,元信息类标签,就是 HTML 用于描述文档自身的一类标签,它们通常出现在 head 标签中,一般都不会在页面被显示出来。元信息多数情况下是给浏览器、搜索引擎等机器阅读的。
- head 标签:本身并不携带任何信息,它主要是作为盛放其它语义类标签的容器使用。head 标签规定了自身必须是 html 标签中的第一个标签,它的内容必须包含一个 title,并且最多只能包含一个 base。如果文档作为 iframe,或者有其他方式指定了文档标题时,可以允许不包含 title 标签。
- title 标签:表示文档的标题。title 作为元信息,可能会被用在浏览器收藏夹、微信推送卡片、微博等各种场景,这时侯往往是上下文缺失的,所以 title 应该是完整地概括整个网页内容的。
- base 标签:历史遗留标签,是一个非常危险的标签。它的作用是给页面上所有的 URL 相对地址提供一个基础。
- meta 标签:是一组键值对,它是一种通用的元信息表示标签。由
name和content两个属性来定义,name 表示元信息的名,content 则用于表示元信息的值。
<!-- charset 属性在 HTML5 中的简化写法:描述了 HTML 文档自身的编码形式,建议放在 head 的第一个 -->
<meta charset="UTF-8" >
<!-- 具有 http-equiv 属性的 meta:表示执行一个命令 -->
<meta http-equiv="content-type" content="text/html; charset=UTF-8">
<!-- name 为 viewport 的 meta -->
<meta name="viewport" content="width=500, initial-scale=1">
<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1, maximum-scale=1, user-scalable=no">
2
3
4
5
6
7
8
9
application-name:如果页面是 Web application,用这个标签表示应用名称。
author: 页面作者。
description:页面描述,这个属性可能被用于搜索引擎或者其它场合。
generator: 生成页面所使用的工具,主要用于可视化编辑器;如果是手写 HTML 的网页,不需要加这个 meta。
keywords: 页面关键字,对于 SEO 场景非常关键。
referrer: 跳转策略,是一种安全考量。
theme-color: 页面风格颜色,实际并不会影响页面,但是浏览器可能据此调整页面之外的 UI(如窗口边框或者 tab 的颜色)。
2
3
4
5
6
7
# HTML链接:除了a标签,还有哪些标签叫链接
- 链接是 HTML 中的一种机制,它是 HTML 文档和其它文档或者资源的连接关系,在 HTML 中,链接有两种类型。一种是超链接型标签,一种是外部资源链接。
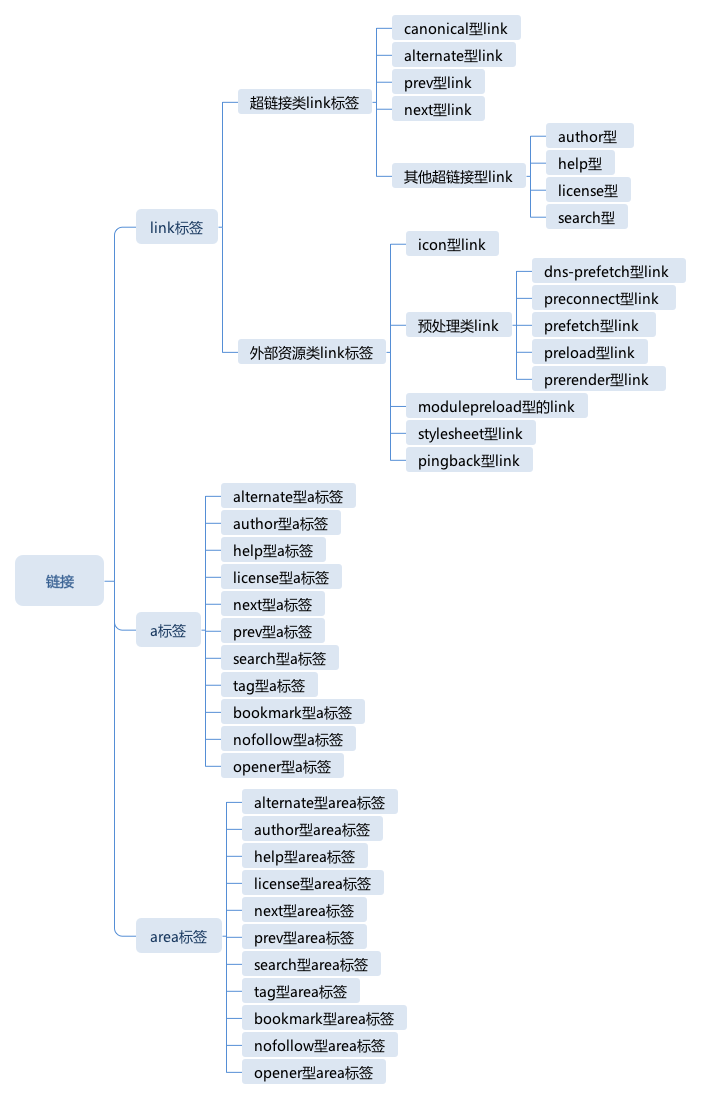
- link 标签:会生成一个链接,它可能生成超链接(被动),也可能生成外部资源链接(主动)。link 标签的链接类型主要通过 rel 属性来区分。
- 超链接类 link 标签:是一种被动型链接,在用户不操作的情况下,它们不会被主动下载。
- 外部资源类 link 标签:会被主动下载,并且根据 rel 类型做不同的处理。把外部的资源链接到文档中,会实际下载这些资源,并且做出一些处理,比如我们常见的用 link 标签引入样式表。【1】icon 型 link:如果没有指定这样的 link,多数浏览器会使用域名根目录下的 favicon.ico,会发送请求。【2】预处理类 link:允许我们控制浏览器,提前针对一些资源去做这一些操作 --> dns 查询域名、建立连接、传输数据、加载进内存和渲染等。【3】modulepreload 型的 link:预先加载一个 JavaScript 的模块,这里的所谓加载,是指完成下载并放入内存,并不会执行对应的 JavaScript。
- a 标签:是 “anchor” 的缩写,它是锚点的意思,标识文档中的特定位置。a 标签其实同时充当了链接和目标点的角色,当 a 标签有 href 属性时,它是链接,当它有 name 时,它是链接的目标。
- area 标签:a 标签基本解决了在页面中插入文字型和整张图片超链接的需要,但是如果我们想要在图片的某个区域产生超链接,那么就要用到 area 标签。与 a 标签非常相似,不同的是,它不是文本型的链接,而是区域型的链接。
- 总结:link 标签一般用于看不见的链接,它可能产生超链接或者外部资源链接,a 和 area 一般用于页面上显示的链接,它们只能产生超链接。
# HTML替换型元素:为什么link一个CSS要用href,而引入js要用src呢
- 一个网页,它是由多个文件构成的,我们在之前的课程中,已经学过了一种引入文件的方案:链接。这节课我们要讲的替换型元素,就是另一种引入文件的方式了。替换型元素是把文件的内容引入,替换掉自身位置的一类标签。
- script:script 标签是为数不多的既可以作为替换型标签,又可以不作为替换型标签的元素。凡是替换型元素,都是使用 src 属性来引用文件的;而链接型元素是使用 href 标签的。style 标签并非替换型元素,不能使用 src 属性来引入 CSS 文件,这样,我们用 link 标签引入 CSS 文件,当然就是用 href 标签啦。
// script 标签的两种用法,这两种写法是等效的:
<script type="text/javascript">
console.log("Hello world!");
</script>
<script type="text/javascript" src="my.js"></script>
2
3
4
5
6
- img:最熟悉的替换型标签就是 img 标签了。【1】从性能的角度考虑,建议你同时给出图片的宽高,因为替换型元素加载完文件后,如果尺寸发生变换,会触发重排版。【2】给 img 加上
alt属性,对于视障用户非常重要,已经做完了可访问性的一半。【3】srcset和sizes,这两个属性的作用是在不同的屏幕大小和特性下,使用不同的图片源。 - picture:picture 元素可以根据屏幕的条件为其中的 img 元素提供不同的源。
- video:在 HTML5 早期的设计中,video 标签也是使用 src 属性来引入源文件的,不过,考虑到了各家浏览器支持的视频格式不同,现在的 video 标签提倡使用 source 。
- audio:但比起 video,audio 元素的历史问题并不严重,所以使用 src 也是没有问题的,也可以使用 source 元素来指定源文件。
- iframe:这个标签能够嵌入一个完整的网页;不过在移动端 iframe 受到了相当多的限制,它无法指定大小,里面的内容会被完全平铺到父级页面上;同时很多网页也会通过 http 协议头禁止自己被放入 iframe 中;同时也是各种安全问题的重灾区。任何情况下都不推荐在实际开发中用以前的 iframe。
# HTML小实验:用代码分析HTML标准
- HTML 标准:采用 WHATWG 的 living standard 标准,来描述一个标签,这里的描述分为 6 个部分:
Categories,标签所属的分类;Contexts in which this element can be used,标签能够用在哪里;Content model,标签的内容模型;Tag omission in text/html,标签是否可以省略;Content attributes,内容属性;DOM interface,用 WebIDL 定义的元素类型接口。 - 单页面版 HTML 标准:https://html.spec.whatwg.org/ (opens new window)。
- 代码角度分析 HTML 标准:
var elementDefinations = Array.prototype.map.call(document.querySelectorAll(".element"), e => ({
text:e.innerText,
name:e.childNodes[0].childNodes[0].id.match(/the\-([\s\S]+)\-element:/)?RegExp.$1:null}));
2
3
# HTML语言:DTD到底是什么
- Tim Berners-Lee 当时去设计 HTML,也并非是凭空造出来,他使用了当时已有的一种语言:SGML。严格来说,HTML 是 SGML 中规定的一种格式,SGML 留给 HTML 的重要的遗产:基本语法和 DTD。
- 基本语法:HTML 作为 SGML 的子集,它遵循 SGML 的基本语法:包括标签、转义等。【1】标签语法:标签语法产生元素,我们从语法的角度讲,就用 “标签” 这个术语,我们从运行时的角度讲,就用 “元素” 这个术语。用于描述一个元素的标签分为开始标签、结束标签和自闭合标签。【2】文本语法:一种是普通的文本节点,另一种是 CDATA 文本节点。【3】注释语法:以
<!--开头,以-->结尾。【4】ProcessingInstruction 语法(处理信息):ProcessingInstruction 多数情况下,是给机器看的。 - DTD 语法(文档类型定义):如果是一个上个时代走过来的前端,一定还记得 HTML4.01 有三种 DTD,分别是严格模式、过渡模式和 frameset 模式。这些复杂的 DTD 写法并没有什么实际作用(浏览器根本不会用 SGML 引擎解析它们),因此到了 HTML5,规定了一个简单的,大家都能记住的 DTD:
<!DOCTYPE html>。 - 文本实体:每一个文本实体由
&开头,由;结束,这属于基本语法的规定;文本实体可以用#后跟一个十进制数字,表示字符 Unicode 值。< > &。
# HTML·ARIA:可访问性是只给盲人用的特性么
- HTML 已经是一个完整的语义系统。在实际应用中,还会用到一些它的扩展,ARIA 就是其中重要的一部分。
- ARIA 全称为
Accessible Rich Internet Applications,它表现为一组属性,是用于可访问性的一份标准。关于可访问性,它被提到最多的就是它可以为视觉障碍用户服务,但是这是一个误解。实际上可访问性其实是一个相当大的课题,它的定义包含了各种设备访问、各种环境、各种人群访问的友好性。不单单是永久性的残障人士需要用到可访问性,健康的人也可能在特定时刻处于需要可访问性的环境。 - ARIA,是以交互形式来标注各种元素的一类属性,交互形式往往跟我们直觉中的 “控件” 非常相似。
- 整体来看,ARIA 给 HTML 元素添加的一个核心属性就是
role:我们可以通过 HTML 属性变化来理解这个 JavaScript 组件的状态,读屏软件等三方客户端,就可以理解我们的 UI 变化,这正是 ARIA 标准的意义。
<span role="checkbox" aria-checked="false" tabindex="0" aria-labelledby="chk1-label"></span>
<label id="chk1-label">Remember my preferences</label>
这里我们给一个 span 添加了 checkbox 角色,表示我们这个 span 被用于 checkbox,这意味着我们可能已经用 JS 代码绑定了这个 span 的 click 事件,并且以 checkbox 的交互方式来处理用户操作。
role 的定义是一个树形的继承关系:
roletype ---> widget -> structure -> window
2
3
4
5
6
- Widget 角色:主要是各种可交互的控件。WAI-ARIA 标准中,所有的角色和对应的属性:https://www.w3.org/TR/wai-aria/ (opens new window)。
- structure 角色:文档的结构。其实跟 HTML5 中不少新标签作用重合了,这里建议优先使用 HTML5 标签。这部分角色的作用类似于语义化标签,但是内容稍微有些不同。
- window 角色:弹出的窗体。在网页中有些表示 “新窗口” 的元素。只有三个角色:window、dialog、alertdialog。
# CSS语法:除了属性和选择器,你还需要知道这些带@的规则
- CSS 并没有像 HTML 和 JavaScript 那样的一份标准文档。CSS 语法的最新标准,你可以戳这里查看:https://www.w3.org/TR/css-syntax-3/ (opens new window),这篇文档的阅读体验其实是非常糟糕的,它对 CSS 语法的描述使用了类似 LL 语法分析的伪代码,而且没有描述任何具体的规则。CSS 的顶层样式表由两种规则组成的规则列表构成,一种被称为 at-rule,也就是 at 规则,另一种是 qualified rule,也就是普通规则。
- at 规则:从所有的 CSS 标准里找到所有可能的 at-rule。
@charset:用于提示 CSS 文件使用的字符编码方式,它如果被使用,必须出现在最前面。这个规则只在给出语法解析阶段前使用,并不影响页面上的展示效果。
@import:用于引入一个 CSS 文件,除了 @charset 规则不会被引入,@import 可以引入另一个文件的全部内容。`@import "mystyle.css";`、`@import url("mystyle.css");`。
@media:能够对设备的类型进行一些判断。
@page:用于分页媒体访问网页时的表现设置,页面是一种特殊的盒模型结构,除了页面本身,还可以设置它周围的盒。
@counter-style:产生一种数据,用于定义列表项的表现。
@keyframes:产生一种数据,用于定义动画关键帧。
@fontface:用于定义一种字体,iconfont 技术就是利用这个特性来实现的。
@support:检查环境的特性,它与 media 比较类似。
@namespace:用于跟 XML 命名空间配合的一个规则,表示内部的 CSS 选择器全都带上特定命名空间。
@viewport:用于设置视口的一些特性,不过兼容性目前不是很好,多数时候被 HTML 的 meta 代替。
2
3
4
5
6
7
8
9
10
- 普通规则:qualified rule 主要是由选择器和声明区块构成。声明区块又由属性和值构成。
- 选择器:它有一份独立的标准,我们可以参考这个网址,https://www.w3.org/TR/selectors-4/ (opens new window)。
- 声明区块:声明部分是一个由 “属性: 值” 组成的序列。
- 扩展知识 CSS 函数。
# CSS选择器:如何选中svg里的a元素
- 选择器是什么:选择器是由 CSS 最先引入的一个机制(但随着 document.querySelector 等 API 的加入,选择器已经不仅仅是 CSS 的一部分了)。这一课,重点讲 CSS 选择器的一些机制。选择器的基本意义是,根据一些特征,选中元素树上的一批元素。
把选择器的结构分一下类,那么由简单到复杂可以分成以下几种:
简单选择器:针对某一特征判断是否选中元素。
复合选择器:连续写在一起的简单选择器,针对元素自身特征选择单个元素。
复杂选择器:由“(空格)”“ >”“ ~”“ +”“ ||”等符号连接的复合选择器,根据父元素或者前序元素检查单个元素。
选择器列表:由逗号分隔的复杂选择器,表示“或”的关系。
2
3
4
5
- 简单选择器:是针对某一特征判断是否为选中元素。
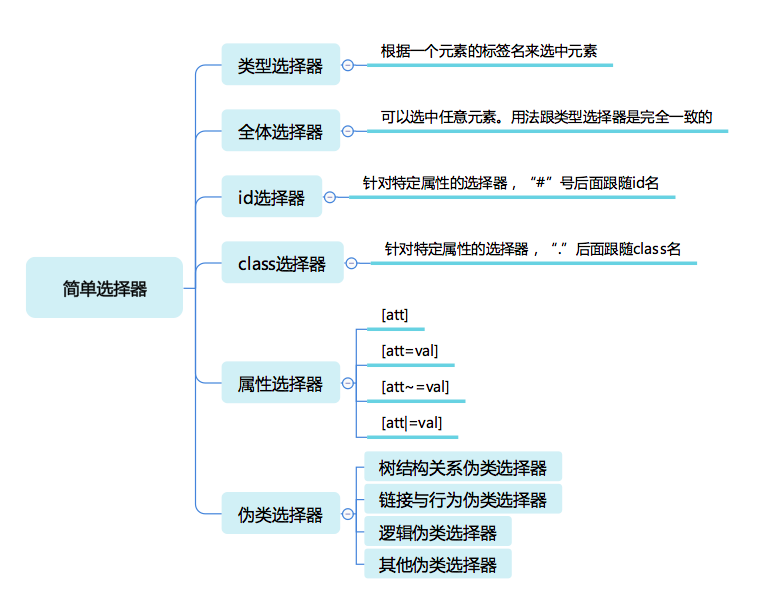
div { }
svg|a { stroke:blue; stroke-width:1; }
html|a { font-size:40px; }
2
3
# CSS选择器:伪元素是怎么回事儿
- 选择器的组合:在 CSS 规则中,选择器部分是一个选择器列表。工程实践中一般会采用设置合理的 class 的方式,来避免过于复杂的选择器结构,这样更有利于维护和性能。
- 选择器的优先级:CSS 标准用一个三元组 (a, b, c) 来构成一个复杂选择器的优先级。id 选择器的数目记为 a;伪类选择器和 class 选择器的数目记为 b;伪元素选择器和标签选择器数目记为 c;“*” 不影响优先级。
CSS 标准建议用一个足够大的进制,获取 “ a-b-c ” 来表示选择器优先级。即:
specificity = base * base * a + base * b + c
其中,base 是一个 “足够大” 的正整数。
行内属性的优先级永远高于 CSS 规则,浏览器提供了一个 “口子”,就是在选择器前加上 “!import”。
2
3
4
5
- 伪元素:本身不单单是一种选择规则,还是一种机制。目前兼容性达到可用的伪元素有以下几种:
::first-line、::first-letter、::before、::after。
::before 表示在元素内容之前插入一个虚拟的元素,::after 则表示在元素内容之后插入。
这两个伪元素所在的 CSS 规则必须指定 content 属性才会生效。
2
# CSS排版:从毕昇开始,我们就开始用正常流了
- 正常流的行为:依次排列,排不下了换行。【1】在正常流基础上,我们有 float 相关规则,使得一些盒占据了正常流需要的空间,我们可以把 float 理解为 “文字环绕”。【2】我们还有 vertical-align 相关规则规定了如何在垂直方向对齐盒。【3】除此之外,margin 折叠是很多人非常不理解的一种设计,但是实际上我们可以把 margin 理解为 “一个元素规定了自身周围至少需要的空间”。
- 正常流的原理:在 CSS 标准中,规定了如何排布每一个文字或者盒的算法,这个算法依赖一个排版的 “当前状态”,CSS 把这个当前状态称为 “格式化上下文(formatting context)”。块级、行内级格式化上下文。
- 正常流的使用技巧:【1】等分布局问题:使用百分比宽度来解决。【2】自适应宽:利用负 margin。
<div class="outer">
<div class="inner"></div>
<div class="inner"></div>
<div class="inner"></div>
</div>
.inner {
width:33.33%;
height:300px;
display:inline-block;
outline:solid 1px blue;
}
效果跟我们预期不同,每个 div 并非紧挨,中间有空白,这是因为我们为了代码格式加入的换行和空格被 HTML 当作空格文本,跟 inline 盒混排了的缘故。
1、解决方案是修改 HTML 代码,去掉空格和换行:
<div class="outer"><div class="inner"></div><div class="inner"></div><div class="inner"></div></div>
2、另一个变通的方案是,改变 outer 中的字号为 0:
.outer {
font-size:0;
}
3、在某些浏览器中,因为像素计算精度问题,还是会出现换行,给 outer 添加一个特定宽度:
.outer {
width:101px;
}
4、这个代码在某些旧版本浏览器中会出现换行。为了保险起见,给最后一个 div 加上一个负的右 margin:
.inner:last-child {
margin-right:-5px;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# CSS Flex排版:为什么垂直居中这么难
- CSS 三大经典问题:垂直居中问题,两列等高问题,自适应宽问题。机智的前端开发者们,曾经创造了各种黑科技来解决问题,包括著名的 table 布局、负 margin、float 与 clear 等等。在这种情况下,
Flex布局被随着 CSS3 一起提出。 - Flex 的设计:在英文中是可伸缩的意思,一些翻译会把它译作弹性。核心是
display:flex和flex属性,它们配合使用。具有 display:flex 的元素我们称为 flex 容器,它的子元素或者盒被称作 flex 项。 - Flex 的原理:Flex 布局支持横向和纵向,把 Flex 延伸的方向称为 “主轴”,把跟它垂直的方向称为 “交叉轴”。
# CSS动画与交互:为什么动画要用贝塞尔曲线这么奇怪的东西
CSS 中跟动画相关的属性有两个:
animation和transition。它们背后的原理:贝塞尔曲线。贝塞尔曲线:贝塞尔曲线是一种插值曲线,它描述了两个点之间差值来形成连续的曲线形状的规则。【1】一个量(可以是任何矢量或者标量)从一个值变化到另一个值,如果我们希望它按照一定时间平滑地过渡,就必须要对它进行插值。最基本的情况是按照时间均匀进行的,称其为线性插值;实际上,线性插值不大能满足我们的需要,因此数学上出现了很多其它的插值算法,其中贝塞尔插值法是非常典型的一种。【2】贝塞尔曲线是一种被工业生产验证了很多年的曲线,它最大的特点就是 “平滑”。
K 次贝塞尔插值算法需要 k+1 个控制点。最简单的一次贝塞尔插值就是线性插值,将时间表示为 0 到 1 的区间;“二次贝塞尔插值” 有 3 个控制点,相当于对 P0 和 P1,P1 和 P2 分别做贝塞尔插值,再对结果做一次贝塞尔插值计算;“三次贝塞尔插值” 则是 “两次 ‘二次贝塞尔插值’ 的结果,再做一次贝塞尔插值”。

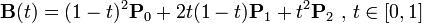
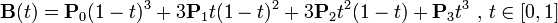
- 贝塞尔曲线的定义中带有一个参数 t,但是这个 t 并非真正的时间,实际上贝塞尔曲线的一个点 (x, y),这里的 x 轴才代表时间。这就造成了一个问题,如果我们使用贝塞尔曲线的直接定义,是没办法直接根据时间来计算出数值的,因此,浏览器中一般都采用了数值算法,其中公认做有效的是牛顿积分。
- 贝塞尔曲线拟合:理论上,贝塞尔曲线可以通过分段的方式拟合任意曲线,但是有一些特殊的曲线,是可以用贝塞尔曲线完美拟合的,比如抛物线。
# CSS渲染:CSS是如何绘制颜色的
- 颜色的原理:最常见的颜色相关的属性就是
color和background-color。【1】RGB 颜色:它符合光谱三原色理论:红、绿、蓝三种颜色的光可以构成所有的颜色。红绿蓝三种颜色的光混合起来就是白光,没有光就是黑暗,所以在 RGB 表示法中,三色数值最大表示白色,三色数值为 0 表示黑色。【2】CMYK 颜色:颜料三原色其实是红、绿、蓝的补色,也就是:品红、黄、青。参考印刷行业的习惯,会尽量优先使用黑色。【3】HSL 颜色:前面的颜色是从人类的视觉原理建模,但是人类对颜色的认识却并非来自自己的神经系统,当我们把阳光散射,可以得到七色光:红橙黄绿蓝靛紫。对人的感知来说,颜色远远大于红、绿、蓝。因此,HSL 这样的颜色模型被设计出来了,它用一个值来表示人类认知中的颜色,我们用专业的术语叫做色相(H),加上颜色的纯度(S)和明度(L),就构成了一种颜色的表示。 - 其它颜色:RGBA,是代表 Red(红色)、Green(绿色)、Blue(蓝色)和 Alpha 的色彩空间。RGBA 颜色被用来表示带透明度的颜色,实际上,Alpha 通道类似一种颜色值的保留字。在 CSS 中,Alpha 通道被用于透明度。
- 渐变:在 CSS 中,
background-image这样的属性,可以设为渐变。CSS 中支持两种渐变,一种是线性渐变,一种是放射性渐变。
linear-gradient(direction, color-stop1, color-stop2, ...);
radial-gradient(shape size at position, start-color, ..., last-color);
2
- 形状:CSS 中的很多属性还会产生形状,比如我们常见的属性:
border、box-shadow、border-radius。
# CSS小实验:动手做,用代码挖掘CSS属性
- 浏览器中已经实现的属性:枚举
document.body.style上的所有属性,并且去掉webkit前缀的私有属性。
Object.keys(document.body.style).filter(e => !e.match(/^webkit/));
- 小实验:找出 W3C 标准中的 CSS 属性。
第一步:找到 CSS 相关的标准。
来到 W3C 的 TR 页面:https://www.w3.org/TR/?tag=css。
从这个页面里抓取所有的标准名称和链接,打开它的代码,我们会发现它是有规律的,这个页面由一个巨大的列表构成,我们只需要根据 tag 选取需要的标准即可。
document.querySelectorAll("#container li[data-tag~=css] h2:not(.Retired):not(.GroupNote)");
第二步:分析每个标准中的 CSS 属性。
经过分析,我们会发现,属性总是在一个具有 propdef 的容器中,有属性 data-dfn-type 值为 property。
document.querySelectorAll(".propdef [data-dfn-type=property]");
第三步:我们来用 iframe 打开这些标准,并且用我们分析好的规则,来找出里面的属性。
var iframe = document.createElement("iframe");
document.body.appendChild(iframe);
iframe.src = "https://www.w3.org/TR/2019/WD-css-lists-3-20190425/";
function happen(element, type){
return new Promise(resolve => {
element.addEventListener(type, resolve, {once: true})
})
};
happen(iframe, "load").then(function(){
//Array.prototype.map.call(document.querySelectorAll("#container li[data-tag~=css] h2"), e=> e.children[0].href + " |\t" + e.children[0].textContent).join("\n")
console.log(iframe.contentWindow);
});
async function start(){
var output = []
for(let standard of Array.prototype.slice.call(document.querySelectorAll("#container li[data-tag~=css] h2:not(.Retired):not(.GroupNote)"))) {
console.log(standard.children[0].href);
iframe.src = standard.children[0].href;
await happen(iframe, "load");
var properties = Array.prototype.map.call(iframe.contentWindow.document.querySelectorAll(".propdef [data-dfn-type=property]"), e => e.childNodes[0].textContent);
if(properties.length)
output.push(standard.children[0].textContent + " | " + properties.join(", "));
}
console.log(output.join("\n"))
};
start();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 4. 模块三:浏览器实现原理与API
# 浏览器:一个浏览器是如何工作的?(阶段一 HTTP)
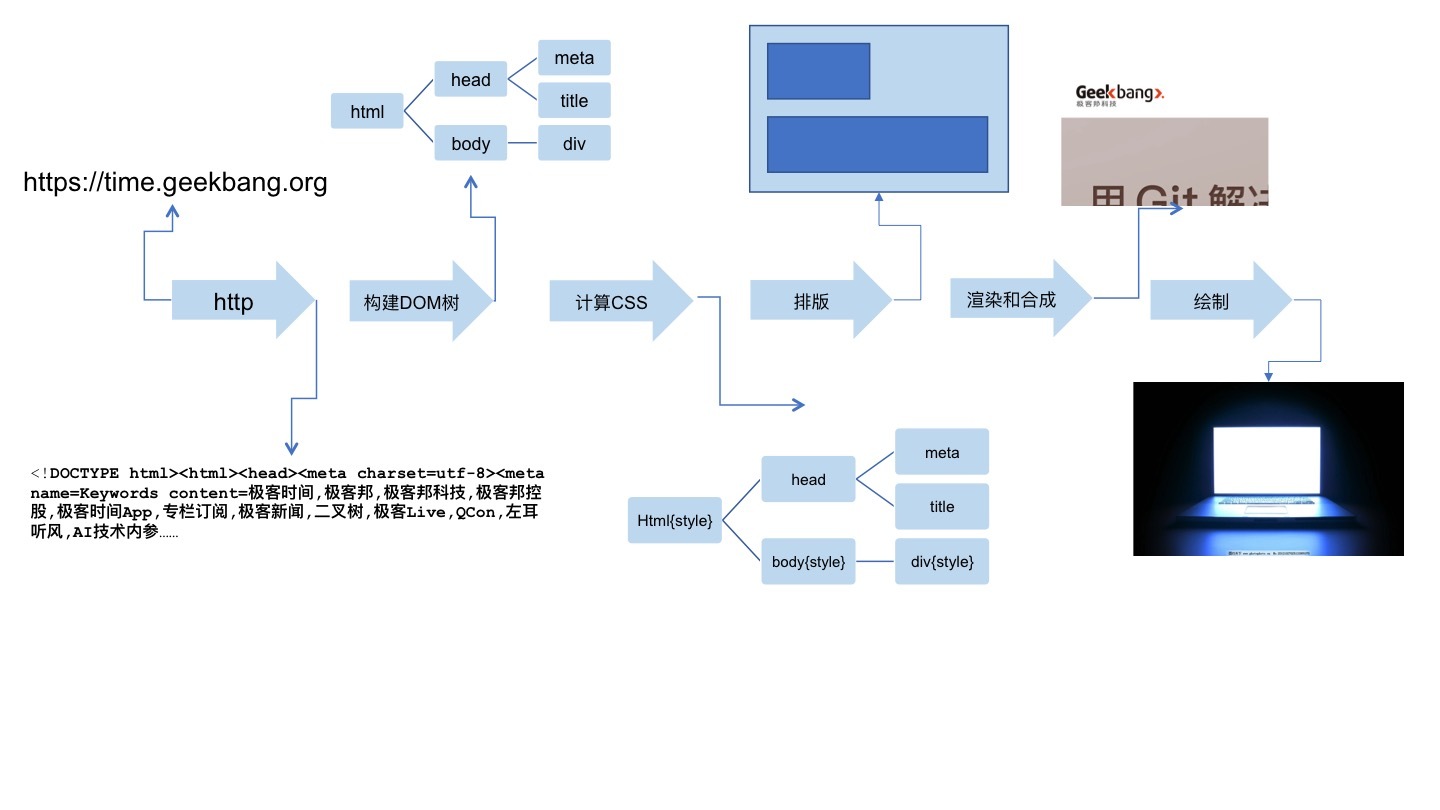
- 浏览器所实现的功能,就是把一个 URL 变成一个屏幕上显示的网页。从 HTTP 请求回来,就产生了流式的数据,即不需要等到上一步骤完全结束,就开始处理上一步的输出,这样我们在浏览网页时,才会看到逐步出现的页面。整个过程是这样的:
浏览器首先使用 HTTP 协议或者 HTTPS 协议,向服务端请求页面;
把请求回来的 HTML 代码经过解析,构建成 DOM 树;
计算 DOM 树上的 CSS 属性;
最后根据 CSS 属性对元素逐个进行渲染,得到内存中的位图;
一个可选的步骤是对位图进行合成,这会极大地增加后续绘制的速度;
合成之后,再绘制到界面上。
2
3
4
5
6
- HTTP 协议:由 IETF 组织制定,跟它相关的标准主要有两份:https://tools.ietf.org/html/rfc2616 (opens new window)、https://datatracker.ietf.org/doc/html/rfc7234 (opens new window)。HTTP 协议是基于 TCP 协议出现的,对 TCP 协议来说,TCP 协议是一条双向的通讯通道,HTTP 在 TCP 的基础上,规定了 Request-Response 模式,这个模式决定了通讯必定是由浏览器端首先发起的。大部分情况下,浏览器的实现者只需要用一个 TCP 库,甚至一个现成的 HTTP 库就可以搞定浏览器的网络通讯部分。HTTP 是纯粹的文本协议,它是规定了使用 TCP 协议来传输文本格式的一个应用层协议。在 TCP 通道中传输的,完全是文本。
实验:使用 telnet 客户端(一个纯粹的 TCP 连接工具)。
1、首先运行 telnet,连接到极客时间主机,在命令行里输入以下内容:
telnet time.geekbang.org 80
2、这个时候,TCP 连接已经建立,我们输入以下字符作为请求:
GET / HTTP/1.1
Host: time.geekbang.org
3、按下两次回车,我们收到了服务端的回复。
在 TCP 通道中传输的,完全是文本。
2
3
4
5
6
7
8
9
10
- HTTP 协议格式:大概可以划分成如下部分:
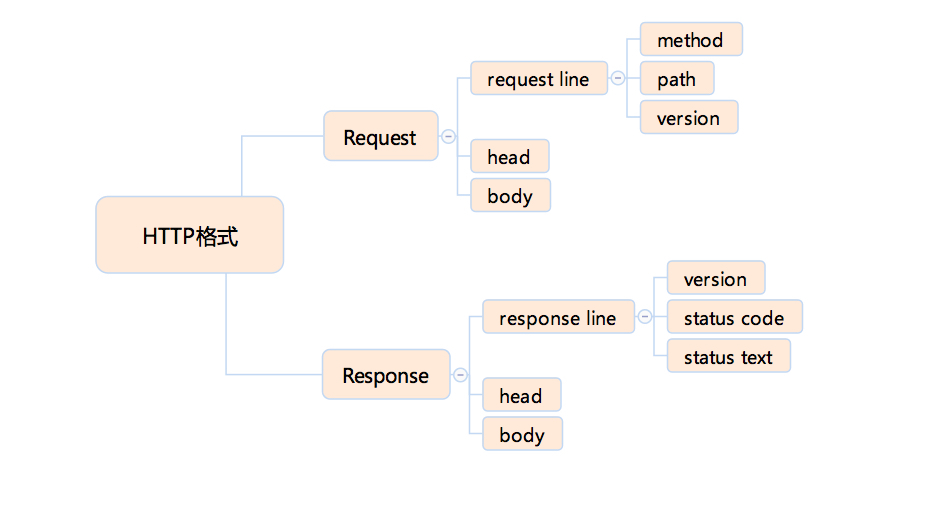
- HTTP Method(方法):表示此次 HTTP 请求希望执行的操作类型。方法有以下几种定义:
GET、POST、HEAD、PUT、DELETE、CONNECT、OPTIONS、TRACE。浏览器通过地址栏访问页面都是 GET 方法;表单提交产生 POST 方法;HEAD 则是跟 GET 类似,只返回响应头,多数由 JavaScript 发起;PUT 和 DELETE 分别表示添加资源和删除资源,但是实际上这只是语义上的一种约定,并没有强约束;CONNECT 现在多用于 HTTPS 和 WebSocket;OPTIONS 和 TRACE 一般用于调试,多数线上服务都不支持。 - HTTP Status code(状态码)和 Status text(状态文本):常见的状态码有以下几种:
1xx:服务器收到请求,临时回应,表示客户端请继续。对前端来说,1xx 系列的状态码是非常陌生的,原因是 1xx 的状态被浏览器 HTTP 库直接处理掉了,不会让上层应用知晓。
2xx:请求成功。--> 200:请求成功。
3xx: 表示请求的目标有变化,希望客户端进一步处理。--> 301&302:永久性与临时性跳转;304:未修改,客户端使用缓存。
4xx:客户端请求错误。--> 403:无权限;404:表示请求的页面不存在;418:It’s a teapot. 这是一个彩蛋,来自 ietf 的一个愚人节玩笑。https://datatracker.ietf.org/doc/html/rfc2324
5xx:服务端请求错误。--> 500:服务端错误;503:服务端暂时性错误,可以一会再试。
2
3
4
5
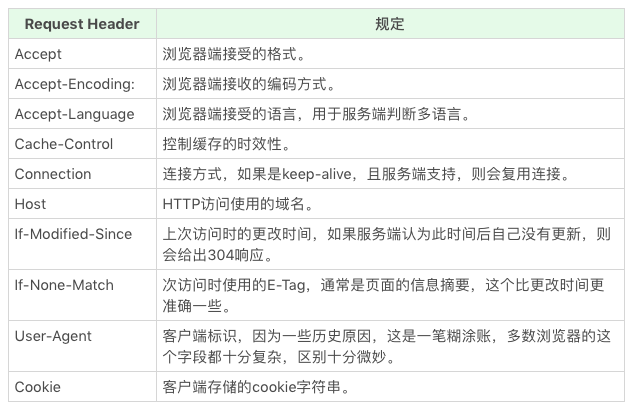
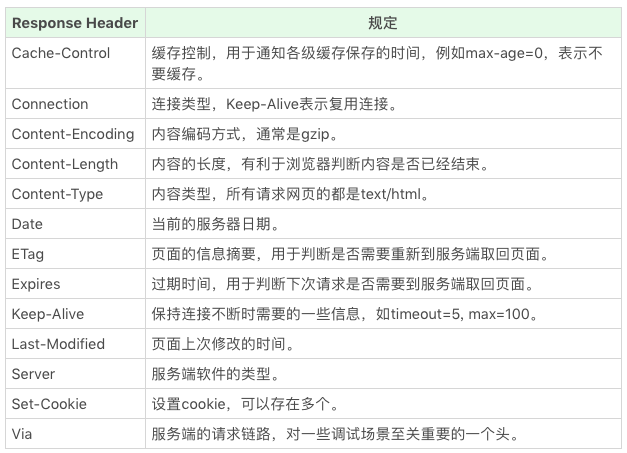
- HTTP Head (HTTP 头):HTTP 头可以看作一个键值对,是一种数据,可以自由定义 HTTP 头和值。在 HTTP 标准中,有完整的请求 / 响应头规定,挑几个重点的说一下:
- HTTP Request Body:常见的 body 格式是:
application/json、application/x-www-form-urlencoded、multipart/form-data、text/xml。使用 HTML 的 form 标签提交产生的 HTML 请求,默认会产生 application/x-www-form-urlencoded 的数据格式,当有文件上传时,则会使用 multipart/form-data。 - HTTPS:在 HTTP 协议的基础上,HTTPS 和 HTTP2 规定了更复杂的内容,但是它基本保持了 HTTP 的设计思想,即:使用 Request-Response 模式。HTTPS 有两个作用,一是确定请求的目标服务端身份,二是保证传输的数据不会被网络中间节点窃听或者篡改。https://tools.ietf.org/html/rfc2818 (opens new window)。HTTPS 是使用加密通道来传输 HTTP 的内容,但是 HTTPS 首先与服务端建立一条 TLS 加密通道。TLS 构建于 TCP 协议之上,它实际上是对传输的内容做一次加密,所以从传输内容上看,HTTPS 跟 HTTP 没有任何区别。
- HTTP 2:是 HTTP 1.1 的升级版本,https://tools.ietf.org/html/rfc7540 (opens new window)。最大的改进有两点,一是支持服务端推送,二是支持 TCP 连接复用。【1】服务端推送能够在客户端发送第一个请求到服务端时,提前把一部分内容推送给客户端,放入缓存当中,这可以避免客户端请求顺序带来的并行度不高,从而导致的性能问题。【2】TCP 连接复用,则使用同一个 TCP 连接来传输多个 HTTP 请求,避免了 TCP 连接建立时的三次握手开销,和初建 TCP 连接时传输窗口小的问题。
# 浏览器:一个浏览器是如何工作的?(阶段二 解析HTML、构建DOM树)
- 解析代码:对应着 HTTP 的 Response 的 body 部分。HTML 的结构不算太复杂,我们日常开发需要的 90% 的“词”(指编译原理的术语 token,表示最小的有意义的单元),种类大约只有标签开始、属性、标签结束、注释、CDATA 节点几种。
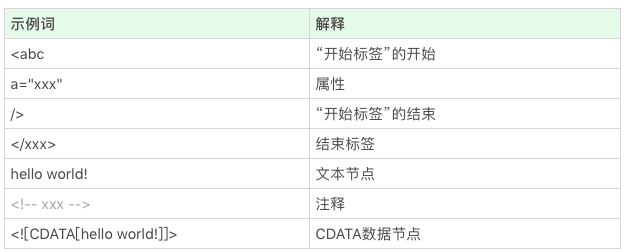
1. 词(token)是如何被拆分的
先来看看一个非常标准的标签,会被如何拆分:<p class="a">text text text</p>。
最小的意义单元其实是 <p,所以这是第一个词(token),<p “标签开始” 的开始;
class=“a” 属性;
> “标签开始” 的结束;
text text text 文本;
</p> 标签结束。
2. 状态机:浏览器工程师要想实现把字符流解析成词(token),最常见的方案就是使用状态机。
绝大多数语言的词法部分都是用状态机实现的。
完整的 HTML 词法状态机,https://html.spec.whatwg.org/multipage/parsing.html#tokenization,官方文档规定了 80 个状态。
状态机设计属于编译原理的基本知识。
2
3
4
5
6
7
8
9
10
11
12
- 构建 DOM 树:把这些简单的词变成 DOM 树,这个过程是使用栈来实现的。根据一些编译原理中常见的技巧,我们使用的栈正是用于匹配开始和结束标签的方案。
function HTMLSyntaticalParser(){
var stack = [new HTMLDocument];
this.receiveInput = function(token) {
//……
}
this.getOutput = function(){
return stack[0];
}
}
// receiveInput 负责接收词法部分产生的词(token),通常可以由 emitToken 来调用
// 在接收的同时,即开始构建 DOM 树,所以我们的主要构建 DOM 树的算法,就写在 receiveInput 当中
2
3
4
5
6
7
8
9
10
11
- 当我们的源代码完全遵循 XHTML(这是一种比较严谨的 HTML 语法)时,描述起来非常简单,而 HTML 也具有很强的容错能力,奥妙在于当 tag end 跟栈顶的 start tag 不匹配的时候如何处理。于是,这又有一个极其复杂的规则,幸好 W3C 又一次很贴心地把全部规则都整理地很好,我们只要翻译成对应的代码就好了,http://www.w3.org/html/wg/drafts/html/master/syntax.html#tree-construction (opens new window)。
# 浏览器:一个浏览器是如何工作的(阶段三 计算CSS)
- 浏览器是如何把 CSS 规则应用到节点上,并给这棵朴素的 DOM 树添加上 CSS 属性的。
- 整体过程:浏览器会尽量流式处理整个过程,构建 DOM 的过程是:从父到子,从先到后,一个一个节点构造,并且挂载到 DOM 树上的,在这个过程中,能同步的把 CSS 属性计算出来。所谓的 CSS 选择器,应该被理解成 “匹配器” 才更合适。
- 选择器的出现顺序,必定跟构建 DOM 树的顺序一致。这是一个 CSS 设计的原则,即保证选择器在 DOM 树构建到当前节点时,已经可以准确判断是否匹配,不需要后续节点信息。
- 作为一门语言,CSS 需要先经过词法分析和语法分析,变成计算机能够理解的结构。这部分具体的做法属于编译原理的内容,这里就不做赘述了。这里假设 CSS 已经被解析成了一棵可用的抽象语法树。一个 compound-selector 是检查一个元素的规则,而一个复合型选择器,则是由数个 compound-selector 通过符号连接起来的。
# 浏览器:一个浏览器是如何工作的?(阶段四 排版)
- 确定每一个元素的位置,基本原则仍然不变,就是尽可能流式地处理上一步骤的输出。
- 基本概念:“排版” 这个概念最初来自活字印刷,是指我们把一个一个的铅字根据文章顺序,放入板框当中的步骤,排版的意思是确定每一个字的位置。在现代浏览器中,仍然借用了这个概念,但是排版的内容更加复杂,包括文字、图片、图形、表格等等,我们把浏览器确定它们位置的过程,叫作排版。
- 浏览器最基本的排版方案是正常流排版,它包含了顺次排布和折行等规则。在正常流的基础上,浏览器支持两类元素:绝对定位元素(把自身从正常流抽出,不参加排版计算,也不影响其它元素)和浮动元素(使得自己在正常流的位置向左或者向右移动到边界,并且占据一块排版空间)。除了正常流,浏览器还支持其它排版方式,比如现在非常常用的 Flex 排版。
# 浏览器:一个浏览器是如何工作的?(阶段五 渲染、合成、绘制)
- 在之前的文章中,已经把 URL 变成字符流,把字符流变成词(token)流,把词(token)流构造成 DOM 树,把不含样式信息的 DOM 树应用 CSS 规则,变成包含样式信息的 DOM 树,并且根据样式信息,计算了每个元素的位置和大小。最后的步骤,就是根据这些样式信息和大小信息,为每个元素在内存中渲染它的图形,并且把它绘制到对应的位置。
- 渲染:在计算机图形学领域里,英文 render 这个词是一个简写,它是特指把模型变成位图的过程。我们把 render 翻译成 “渲染”,是个非常有意思的翻译,中文里 “渲染” 这个词是一种绘画技法,是指沾清水把墨涂开的意思。这里的位图就是在内存里建立一张二维表格,把一张图片的每个像素对应的颜色保存进去(位图信息也是 DOM 树中占据浏览器内存最多的信息,我们在做内存占用优化时,主要就是考虑这一部分)。【1】浏览器中渲染这个过程,就是把每一个元素对应的盒变成位图。这个渲染过程是非常复杂的,但是总体来说,可以分成两个大类:图形和文字。【2】盒的背景、边框、SVG 元素、阴影等特性,都是需要绘制的图形类。这就像我们实现 HTTP 协议必须要基于 TCP 库一样,这一部分,我们需要一个底层库来支持。盒中的文字,也需要用底层库来支持,叫做字体库,字体库提供读取字体文件的基本能力,它能根据字符的码点抽取出字形。字形分为像素字形和矢量字形两种。【3】渲染的过程,是不会把子元素绘制到渲染的位图上的,这样,当父子元素的相对位置发生变化时,可以保证渲染的结果能够最大程度被缓存,减少重新渲染。
- 合成:是英文术语 compositing 的翻译,这个过程实际上是一个性能考量,它并非实现浏览器的必要一环。合成的过程,就是为一些元素创建一个 “合成后的位图”(我们把它称为合成层),把一部分子元素渲染到合成的位图上面。好的合成策略是 “猜测” 可能变化的元素,把它排除到合成之外。新的 CSS 标准中,规定了 will-change 属性,可以由业务代码来提示浏览器的合成策略,灵活运用这样的特性,可以大大提升合成策略的效果。
- 绘制:是把 “位图最终绘制到屏幕上,变成肉眼可见的图像” 的过程,一般来说浏览器并不需要用代码来处理这个过程,浏览器只需要把最终要显示的位图交给操作系统即可。一般最终位图位于显存中。绘制过程,实际上就是按照 z-index 把它们依次绘制到屏幕上。“重排” 和 “重绘”,前者讲的是我们上一课的排版行为,后者模糊地指向了我们本课程三小节讲的三个步骤,而实际上这个说法大体不能算错,却不够准确。“绘制” 发生的频率比我们想象中要高得多(如鼠标划过浏览器显示区域)。
# 浏览器DOM:你知道HTML的节点有哪几种吗
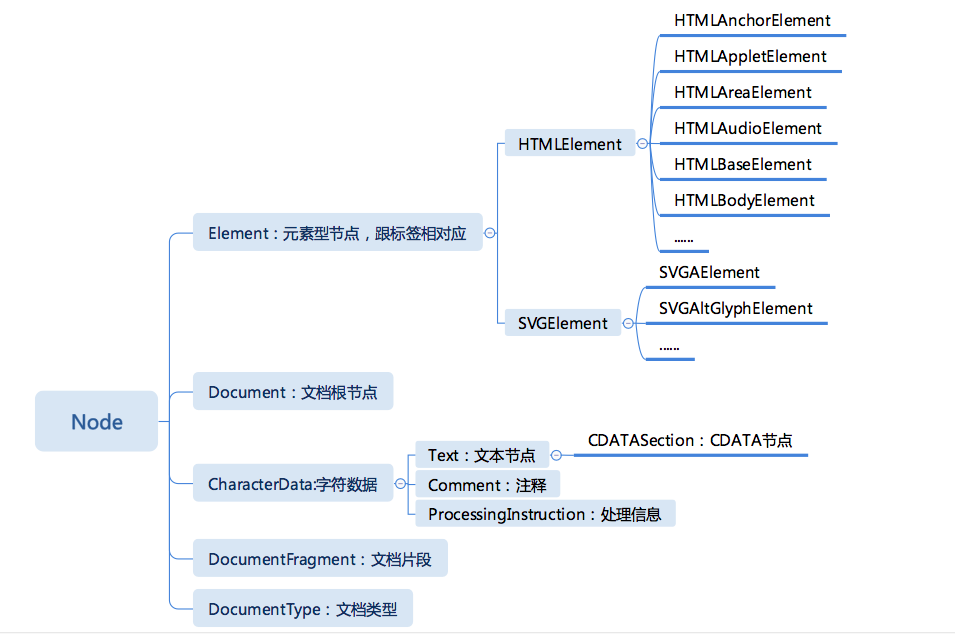
- DOM API 是最早被设计出来的一批 API,也是用途最广的 API,所以早年的技术社区,常常用 DOM 来泛指浏览器中所有的 API。不过今天这里我们要介绍的 DOM,指的就是狭义的文档对象模型。
- DOM API 介绍:文档对象模型是用来描述文档,这里的文档,是特指 HTML 文档。HTML 文档是一个由标签嵌套而成的树形结构,因此 DOM 也是使用树形的对象模型来描述一个 HTML 文档。
DOM API 大致会包含 4 个部分:
节点:DOM 树形结构中的节点相关 API。
事件:触发和监听事件相关 API。
Range:操作文字范围相关 API。
遍历:遍历 DOM 需要的 API。
2
3
4
5
- 节点:DOM 的树形结构所有的节点有统一的接口 Node,按照继承关系,介绍一下节点的类型。【1】在编写 HTML 代码并且运行后,就会在内存中得到这样一棵 DOM 树,HTML 的写法会被转化成对应的文档模型,而我们则可以通过 JavaScript 等语言去访问这个文档模型。【2】DocumentFragment 也非常有用,它常常被用来高性能地批量添加节点。
在这些节点中,除了 Document 和 DocumentFrangment,都有与之对应的 HTML 写法:
Element: <tagname>...</tagname>
Text: text
Comment: <!-- comments -->
ProcessingInstruction: <?a 1?>
DocumentType: <!Doctype html>
2
3
4
5
6
- Node:Node 是 DOM 树继承关系的根节点,它定义了 DOM 节点在 DOM 树上的操作。
1、Node 提供了一组属性,来表示它在 DOM 树中的关系:
parentNode
childNodes
firstChild
lastChild
nextSibling
previousSibling
2、Node 中也提供了操作 DOM 树的 API:
appendChild
insertBefore
removeChild
replaceChild
3、除此之外,Node 还提供了一些高级 API:
compareDocumentPosition 是一个用于比较两个节点中关系的函数。
contains 检查一个节点是否包含另一个节点的函数。
isEqualNode 检查两个节点是否完全相同。
isSameNode 检查两个节点是否是同一个节点,实际上在 JavaScript 中可以用 “===”。
cloneNode 复制一个节点,如果传入参数 true,则会连同子元素做深拷贝。
4、DOM 标准规定了节点必须从文档的 create 方法创建出来,不能够使用原生的 JavaScript 的 new 运算:
createElement
createTextNode
createCDATASection
createComment
createProcessingInstruction
createDocumentFragment
createDocumentType
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
- Element 与 Attribute:Node 提供了树形结构上节点相关的操作。而大部分时候,比较关注的是元素。Element 表示元素,它是 Node 的子类。元素对应了 HTML 中的标签,它既有子节点,又有属性,所以 Element 子类中有一系列操作属性的方法。
1、可以把元素的 Attribute 当作字符串来看待,这样就有以下的 API:
getAttribute
setAttribute
removeAttribute
hasAttribute
2、如果追求极致的性能,还可以把 Attribute 当作节点:
getAttributeNode
setAttributeNode
3、如果喜欢 property 一样的访问 attribute,还可以使用 attributes 对象,比如:
document.body.attributes.class = “a” 等效于 document.body.setAttribute(“class”, “a”)。
2
3
4
5
6
7
8
9
10
11
12
- 查找元素:document 节点提供了查找元素的能力。
querySelector
querySelectorAll
getElementById
getElementsByName
getElementsByTagName
getElementsByClassName
1、需要注意,getElementById、getElementsByName、getElementsByTagName、getElementsByClassName,这几个 API 的性能高于 querySelector。
2、而 getElementsByName、getElementsByTagName、getElementsByClassName 获取的集合并非数组,而是一个能够动态更新的集合。这说明浏览器内部是有高速的索引机制,来动态更新这样的集合的。所以,尽管 querySelector 系列的 API 非常强大,我们还是应该尽量使用 getElement 系列的 API。
2
3
4
5
6
7
8
- 遍历:DOM API 中还提供了 NodeIterator 和 TreeWalker 来遍历树。比起直接用属性来遍历,NodeIterator 和 TreeWalker 提供了过滤功能,还可以把属性节点也包含在遍历之内。
// NodeIterator 的基本用法示例如下:
var iterator = document.createNodeIterator(document.body, NodeFilter.SHOW_TEXT | NodeFilter.SHOW_COMMENT, null, false);
var node;
while(node = iterator.nextNode())
{
console.log(node);
}
// TreeWalker 的用法:
var walker = document.createTreeWalker(document.body, NodeFilter.SHOW_ELEMENT, null, false)
var node;
while(node = walker.nextNode())
{
if(node.tagName === "p")
node.nextSibling();
console.log(node);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- Range:Range API 是一个比较专业的领域,如果不做富文本编辑类的业务,不需要太深入。
// 这个例子展示了如何使用 range 来取出元素和在特定位置添加新元素:
var range = new Range(),
firstText = p.childNodes[1],
secondText = em.firstChild
range.setStart(firstText, 9) // do not forget the leading space
range.setEnd(secondText, 4)
var fragment = range.extractContents()
range.insertNode(document.createTextNode("aaaa"))
2
3
4
5
6
7
8
9
# 浏览器CSSOM:如何获取一个元素的准确位置
- CSSOM 是 CSS 的对象模型,在 W3C 标准中,它包含两个部分:描述样式表和规则等 CSS 的模型部分(CSSOM),和跟元素视图相关的 View 部分(CSSOM View)。在实际使用中,CSSOM View 比 CSSOM 更常用一些,因为我们很少需要用代码去动态地管理样式表。
- CSSOM:首先来介绍下 CSS 中样式表的模型,也就是 CSSOM 的本体。样式表只能使用 style 标签或者 link 标签创建。
1、通常创建样式表也都是使用 HTML 标签来做到的,用 style 标签和 link 标签创建样式表,例如:
<style title="Hello">
a {
color:red;
}
</style>
<link rel="stylesheet" title="x" href="data:text/css,p%7Bcolor:blue%7D">
2、CSSOM API 的基本用法,一般来说需要先获取文档中所有的样式表:(一个只读的列表)
document.styleSheets
3、虽然无法用 CSSOM API 来创建样式表,但是可以修改样式表中的内容:
document.styleSheets[0].insertRule("p { color:pink; }", 0)
document.styleSheets[0].removeRule(0)
4、更进一步,可以获取样式表中特定的规则(Rule),并且对它进行一定的操作:
document.styleSheets[0].cssRules
这里的 Rules 可就没那么简单了,它可能是 CSS 的 at-rule,也可能是普通的样式规则。不同的 rule 类型,具有不同的属性。
5、CSSOM 还提供了一个非常重要的方法,来获取一个元素最终经过 CSS 计算得到的属性:
window.getComputedStyle(elt, pseudoElt);
第一个参数就是要获取属性的元素,第二个参数是可选的,用于选择伪元素。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- CSSOM View:CSSOM View 这一部分的 API,可以视为 DOM API 的扩展,它在原本的 Element 接口上,添加了显示相关的功能,这些功能,又可以分成三个部分:窗口部分,滚动部分和布局部分。
1、窗口 API:用于操作浏览器窗口的位置、尺寸等。
moveTo(x, y) 窗口移动到屏幕的特定坐标;
moveBy(x, y) 窗口移动特定距离;(相对定位)
resizeTo(x, y) 改变窗口大小到特定尺寸;
resizeBy(x, y) 改变窗口大小特定尺寸。(相对定位)
窗口 API 还规定了 window.open() 的第三个参数:
window.open("about:blank", "_blank" ,"width=100,height=100,left=100,right=100")
2、滚动 API:要建立一个概念,在 PC 时代,浏览器可视区域的滚动和内部元素的滚动关系是比较模糊的。视口滚动 API 是页面的顶层容器的滚动,大部分移动端浏览器都会采用一些性能优化,它和元素滚动不完全一样,请大家一定建立这个区分的意识。
- 视口滚动 API:可视区域(视口)滚动行为由 window 对象上的一组 API 控制。
scrollX 是视口的属性,表示 X 方向上的当前滚动距离,有别名 pageXOffset;
scrollY 是视口的属性,表示 Y 方向上的当前滚动距离,有别名 pageYOffset;
scroll(x, y) 使得页面滚动到特定的位置,有别名 scrollTo,支持传入配置型参数 {top, left};
scrollBy(x, y) 使得页面滚动特定的距离,支持传入配置型参数 { top, left }。
监听视口滚动事件,需要在 document 对象上绑定事件监听函数:
document.addEventListener("scroll", function(event){
//......
})
- 元素滚动 API:在 Element 类(参见 DOM 部分),为了支持滚动,加入了以下 API。
scrollTop 元素的属性,表示 Y 方向上的当前滚动距离。
scrollLeft 元素的属性,表示 X 方向上的当前滚动距离。
scrollWidth 元素的属性,表示元素内部的滚动内容的宽度,一般来说会大于等于元素宽度。
scrollHeight 元素的属性,表示元素内部的滚动内容的高度,一般来说会大于等于元素高度。
scroll(x, y) 使得元素滚动到特定的位置,有别名 scrollTo,支持传入配置型参数 { top, left }。
scrollBy(x, y) 使得元素滚动特定的距离,支持传入配置型参数 { top, left }。
scrollIntoView(arg) 滚动元素所在的父元素,使得元素滚动到可见区域,可以通过 arg 来指定滚到中间、开始或者就近。
可滚动的元素也支持 scroll 事件,在元素上监听它的事件即可:
element.addEventListener("scroll", function(event){
//......
})
3、布局 API:是整个 CSSOM 中最常用到的部分,同样要分成全局 API 和元素上的 API。
- 全局尺寸信息:window 对象上提供,是通过属性来提供的。
window.innerHeight, window.innerWidth 这两个属性表示视口的大小。
window.outerWidth, window.outerHeight 这两个属性表示浏览器窗口占据的大小,很多浏览器没有实现,一般来说这两个属性无关紧要。
window.devicePixelRatio 这个属性非常重要,表示物理像素和 CSS 像素单位的倍率关系,Retina 屏这个值是 2,后来也出现了一些 3 倍的 Android 屏。
window.screen (屏幕尺寸相关的信息)
window.screen.width, window.screen.height 设备的屏幕尺寸。
window.screen.availWidth, window.screen.availHeight 设备屏幕的可渲染区域尺寸,一些 Android 机器会把屏幕的一部分预留做固定按钮,所以有这两个属性,实际上一般浏览器不会实现的这么细致。
window.screen.colorDepth, window.screen.pixelDepth 这两个属性是固定值 24,应该是为了以后预留。
- 元素的布局信息:获取宽高的对象应该是 “盒”,getClientRects(); getBoundingClientRect()。
如果我们要获取相对坐标,或者包含滚动区域的坐标,需要一点小技巧:
var offsetX = document.documentElement.getBoundingClientRect().x - element.getBoundingClientRect().x;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
- 应该从脑中消除 “元素有宽高” 这样的概念,课程中已经多次提到了,有些元素可能产生多个盒(
display:inline;),事实上,只有盒有宽和高,元素是没有的。
# 浏览器事件:为什么会有捕获过程和冒泡过程
- 事件概述:事件来自输入设备,输入设备有三种:键盘;鼠标;触摸屏。【1】其中,触摸屏和鼠标又有一定的共性,它们被称作 pointer 设备,所谓 pointer 设备,是指它的输入最终会被抽象成屏幕上面的一个点。但是触摸屏和鼠标又有一定区别,它们的精度、反应时间和支持的点的数量都不一样。【2】现代的 UI 系统,都源自 WIMP 系统。WIMP 即 Window Icon Menu Pointer 四个要素。
- 捕获与冒泡:实际上点击事件来自触摸屏或者鼠标,鼠标点击并没有位置信息,但是一般操作系统会根据位移的累积计算出来,跟触摸屏一样,提供一个坐标给浏览器。把这个坐标转换为具体的元素上事件的过程,就是捕获过程了。而冒泡过程,则是符合人类理解逻辑的:当你按电视机开关时,你也按到了电视机。捕获是计算机处理事件的逻辑,而冒泡是人类处理事件的逻辑。
- 焦点:pointer 事件是由坐标控制,键盘事件是由焦点系统控制。一般来说,操作系统也会提供一套焦点系统,但是现代浏览器一般都选择在自己的系统内覆盖原本的焦点系统。焦点系统认为整个 UI 系统中,有且仅有一个 “聚焦” 的元素,所有的键盘事件的目标元素都是这个聚焦元素。(Tab 键;浏览器 API:focus() 、blur())
- 自定义事件:只能在 DOM 元素上使用自定义事件。使用 Event 构造器来创造了一个新的事件,然后调用 dispatchEvent 来在特定元素上触发。
// 代码示例如下(来自 MDN):
var evt = new Event("look", { "bubbles":true, "cancelable":false });
document.dispatchEvent(evt);
2
3
# 浏览器API(小实验):动手整理全部API
- 按照每个 API 所在的标准来分类。用代码来反射浏览器环境中全局对象的属性,然后用 JavaScript 的 filter 方法来逐步过滤掉已知的属性。
Object.getOwnPropertyNames(window);
{
let js = new Set();
let objects = ["BigInt", "BigInt64Array", "BigUint64Array", "Infinity", "NaN", "undefined", "eval", "isFinite", "isNaN", "parseFloat", "parseInt", "decodeURI", "decodeURIComponent", "encodeURI", "encodeURIComponent", "Array", "Date", "RegExp", "Promise", "Proxy", "Map", "WeakMap", "Set", "WeakSet", "Function", "Boolean", "String", "Number", "Symbol", "Object", "Error", "EvalError", "RangeError", "ReferenceError", "SyntaxError", "TypeError", "URIError", "ArrayBuffer", "SharedArrayBuffer", "DataView", "Float32Array", "Float64Array", "Int8Array", "Int16Array", "Int32Array", "Uint8Array", "Uint16Array", "Uint32Array", "Uint8ClampedArray", "Atomics", "JSON", "Math", "Reflect", "escape", "unescape"];
objects.forEach(o => js.add(o));
let names = Object.getOwnPropertyNames(window)
names = names.filter(e => !js.has(e));
}
2
3
4
5
6
7
8
- DOM 中的元素构造器:把所有 Node 的子类都过滤掉,再把 Node 本身也过滤掉。
names = names.filter( e => {
try {
return !(window[e].prototype instanceof Node)
} catch(err) {
return true;
}
}).filter( e => e != "Node")
2
3
4
5
6
7
- Window 对象上的属性:找到 Window 对象的定义,https://html.spec.whatwg.org/#window (opens new window)。
// 从浏览器 Window 对象的属性中去掉某些函数和属性
{
let names = Object.getOwnPropertyNames(window)
let js = new Set();
let objects = ["BigInt", "BigInt64Array", "BigUint64Array", "Infinity", "NaN", "undefined", "eval", "isFinite", "isNaN", "parseFloat", "parseInt", "decodeURI", "decodeURIComponent", "encodeURI", "encodeURIComponent", "Array", "Date", "RegExp", "Promise", "Proxy", "Map", "WeakMap", "Set", "WeakSet", "Function", "Boolean", "String", "Number", "Symbol", "Object", "Error", "EvalError", "RangeError", "ReferenceError", "SyntaxError", "TypeError", "URIError", "ArrayBuffer", "SharedArrayBuffer", "DataView", "Float32Array", "Float64Array", "Int8Array", "Int16Array", "Int32Array", "Uint8Array", "Uint16Array", "Uint32Array", "Uint8ClampedArray", "Atomics", "JSON", "Math", "Reflect", "escape", "unescape"];
objects.forEach(o => js.add(o));
names = names.filter(e => !js.has(e));
names = names.filter( e => {
try {
return !(window[e].prototype instanceof Node)
} catch(err) {
return true;
}
}).filter( e => e != "Node")
let windowprops = new Set();
objects = ["window", "self", "document", "name", "location", "history", "customElements", "locationbar", "menubar", " personalbar", "scrollbars", "statusbar", "toolbar", "status", "close", "closed", "stop", "focus", " blur", "frames", "length", "top", "opener", "parent", "frameElement", "open", "navigator", "applicationCache", "alert", "confirm", "prompt", "print", "postMessage", "console"];
objects.forEach(o => windowprops.add(o));
names = names.filter(e => !windowprops.has(e));
}
// 还要过滤掉所有的事件,也就是 on 开头的属性
names = names.filter( e => !e.match(/^on/))
// webkit 前缀的私有属性我们也过滤掉
names = names.filter( e => !e.match(/^webkit/))
// 在 HTML 标准中还能找到所有的接口,这些也过滤掉
let interfaces = new Set();
objects = ["ApplicationCache", "AudioTrack", "AudioTrackList", "BarProp", "BeforeUnloadEvent", "BroadcastChannel", "CanvasGradient", "CanvasPattern", "CanvasRenderingContext2D", "CloseEvent", "CustomElementRegistry", "DOMStringList", "DOMStringMap", "DataTransfer", "DataTransferItem", "DataTransferItemList", "DedicatedWorkerGlobalScope", "Document", "DragEvent", "ErrorEvent", "EventSource", "External", "FormDataEvent", "HTMLAllCollection", "HashChangeEvent", "History", "ImageBitmap", "ImageBitmapRenderingContext", "ImageData", "Location", "MediaError", "MessageChannel", "MessageEvent", "MessagePort", "MimeType", "MimeTypeArray", "Navigator", "OffscreenCanvas", "OffscreenCanvasRenderingContext2D", "PageTransitionEvent", "Path2D", "Plugin", "PluginArray", "PopStateEvent", "PromiseRejectionEvent", "RadioNodeList", "SharedWorker", "SharedWorkerGlobalScope", "Storage", "StorageEvent", "TextMetrics", "TextTrack", "TextTrackCue", "TextTrackCueList", "TextTrackList", "TimeRanges", "TrackEvent", "ValidityState", "VideoTrack", "VideoTrackList", "WebSocket", "Window", "Worker", "WorkerGlobalScope", "WorkerLocation", "WorkerNavigator"];
objects.forEach(o => interfaces.add(o));
names = names.filter(e => !interfaces.has(e));
// 这样过滤之后,已经过滤掉了所有的事件、Window 对象、JavaScript 全局对象和 DOM 相关的属性
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
- 其它属性:
// 把过滤的代码做一下抽象,写成一个函数:
function filterOut(names, props) {
let set = new Set();
props.forEach(o => set.add(o));
return names.filter(e => !set.has(e));
}
还需要过滤的一些属性:(注意冒号后面的才是属性)
1 - ECMAScript 2018 Internationalization API:Intl 等等。
2 - Streams 标准:ByteLengthQueuingStrategy 等等。
3 - WebGL 标准:WebGLContextEvent 等等。
4 - Web Audio API:WaveShaperNode 等等。
5 - Encoding 标准:TextDecoder 等等。
6 - Web Background Synchronization:SyncManager等等。
7 - Web Cryptography API:SubtleCrypto 等等。
8 - Media Source Extensions:SourceBufferList 等等。
9 - The Screen Orientation API:ScreenOrientation 等等。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 结语:在整理 API 的过程中,可以找到各种不同组织的标准,比如:ECMA402 标准来自 ECMA;Encoding 标准来自 WHATWG;WebGL 标准来自 Khronos;Web Cryptography 标准来自 W3C;还有些 API,根本没有被标准化。(不同的浏览器环境应该略有不同)
- 整理参考:https://gist.github.com/aimergenge/c0fb01dbdbf3aa1c2b31e3f2ae779274 (opens new window)。
# 5. 模块四:前端综合应用
# 性能:前端的性能到底对业务数据有多大的影响
- 性能总论:一切没有 profiling 的性能都是耍流氓。凡是真正有价值的性能优化,必定是从端到端的业务场景建立体系来考虑的。性能体系的建立可以分成以下几部分:现状评估和建立指标;技术方案;执行;结果评估和监控。
- 现状评估和建立指标:作为一个工程师,指标又要考虑两个因素。一方面,对用户来说,什么样的性能指标能更好地评估它的体验?另一方面,对公司来说,什么样的指标会影响业务价值呢?-- 提升用户体验;提高业务价值。
- 性能问题可以分成很多方面,最重要的几个点是:页面加载性能;动画与操作性能;内存、电量消耗。
- 其实这三部分中,“页面加载性能” 跟用户的流失率有非常强的关联性,而用户流失率,正是公司业务非常看重的指标。
- 用什么指标来衡量页面加载性能呢?最容易想到的方案是 “用户平均加载时间”。但是这个指标有严重的问题。
2
3
- 技术方案:有了指标,就有了优化的目标。网页的加载时间,不但跟体积有关系,还跟请求数有很大关系。设计的技术方案大约可以这样划分:
- 执行:技术方案设计好了,只完成了一半的工作,接下来还需要一个执行过程。执行也不简单,如果说方案主要靠技术,那么执行就是靠工程实施。工程实施可能有不同的程度,把工程水平从低到高分成三个阶段:纯管理;制度化;自动化。
- 结果评估和监控:执行完了之后,就要向老板汇报,还要有一定的结果总结。要有一定长效机制,不能优化完了退化,这些都要求有线上监控机制。要想做线上监控,分两个部分:数据采集;数据展现。
# 工具链:什么样的工具链才能提升团队效率
- 工具总论:跟性能不同,工具体系并非业务结果,所以我们没法用简单的数据指标来衡量工具,它的结果更多程度是一种开发体验:帮助技术团队内的同学提升效率和体验。
- 工具体系的目标:考虑到工程行为都是团队合作,我们对工具最基本的要求就是:版本一致;工具体系的另一个重要需求是:避免冲突。在谈及具体问题之前,必须要有这两个要求的解决方案,这就需要引入一个新的概念:工具链。
- 工具体系的设计:要想设计一个工具链,首先需要整理一下,前端开发大约要做哪些事:初始化项目;运行和调试;测试(单元测试);发布。【1】一个典型的社区项目工具链可能就类似下面这样:Yeoman、webpack、ava/nyc、aws-cli。【2】在稍微大一些的团队内部,往往会需要不止一种开发模式,如移动开发和桌面开发,所需要的工具链也不一样。
- 工具体系的执行:因为工具体系服务的是团队内部成员,所以执行非常简单,同时工具体系的入口是初始化项目,所以只要初始化工具在手,可以控制其它所有工具。工程体系的执行分成三个层次:纯管理、制度化和自动化。工具体系因为其自身特性,可以说是最容易做到自动化的一个体系了。
- 工具体系的监控:工具体系的结果虽然是软性的,也不能完全不做监控。一般来说,以下指标跟开发者体验较为相关:调试 / 构建次数;构建平均时长;使用的工具版本;发布次数。
# 持续集成:几十个前端一起工作,如何保证工作质量
- 持续集成是近现代软件工程中的一个非常重要的概念。它是指在软件开发过程中,以定期或者实时的方式,集成所有人的工作成果,做统一的构建和测试。持续集成还有升级版本:持续交付和持续部署。
- 持续集成总论:传统的持续集成方案放在前端,要么不需要,要么不适用,要么实施成本高,因此不能套用传统的持续集成理论,而需要重新思考前端领域的持续集成体系。
1、传统软件的持续集成主要有以下措施。
- daily build:每日构建,开发者每天提交代码到代码仓库,构建一个可运行的版本。
- build verification test(BVT):构建验证测试,每日构建版本出来后,运行一组自动化的测试用例,保证基本功能可用。
2、对于前端来说,有一些现实的区别:
- 前端代码按页面自然解耦,大部分页面都是单人开发;
- 前端构建逻辑简单,一般开发阶段都保证构建成功,不需要构建;
- 前端代码一般用于开发界面,测试自动化成本极高;
- 前端页面跳转,是基于 url,没有明确的产品边界。
2
3
4
5
6
7
8
9
- 持续集成的目标:一是要及早集成代码形成可测试的版本,二是通过一定的测试来验证提交的代码的有效性。
- 持续集成的方案:预览环境,代替每日构建,前端每次(或指定次)提交代码到仓库都同步到预览环境,保证预览环境总是可用;规则校验,代替构建验证测试,通过数据采集(如前面提到的性能数据)和代码扫描,保证提交的代码满足一定的质量要求。【1】预览环境:预览环境的部署需要机器和域名,只需要在公司内网即可;建立预览环境发布机制。【2】规则校验:页面结构扫描;运行时数据采集;代码扫描。
- 持续集成的实施:必须严格做到自动化和制度化的。需要重点关注校验规则部分,要建立一个民主讨论、定期更新的校验规则。
- 持续集成的结果:持续集成机制的建立本身就可以视为一种结果,它能够让整个团队的代码质量有一个基本的保障,提前发现问题,统一代码风格,从而带来开发体验和效率的提升。
# 搭建系统:大量的低价值需求应该如何应对
- 搭建系统的目标:是解决大量的简单页面生产问题。衡量这个目标的指标应该是生产页面的数量,这部分非常的明确,你如果要做搭建系统,可以根据业务的体量和服务的范围来决定具体的指标要求。
- 搭建系统的设计:大概有几种流派,这里介绍几种常见的搭建系统的设计,数据、模块、模板、页面几种实体的相互作用。【1】第一种,是模板化搭建,由前端工程师生产页面模板,再由运营提供数据来完成页面,可以用以下公式来理解:模板 + 数据 = 页面。模板化搭建是一种简单的思路,它的优点是整个系统实现简单。【2】第二种思路是,模块化搭建,由前端工程师生产模块,由运营把模块和数据组织成页面。【3】第三种思路,是数据驱动界面,这是一种比较新的思路,即数据中包含了展现自身所需要的模块相关的信息,本身决定了界面。
- 数据:是用于展现界面所需要的信息。按照数据用途,可以分成界面配置数据和内容数据;按照数据来源,可以分成运营人员手工填写的数据和来自 API 产生的数据。搭建系统的数据部分有两个难点:第一个难点是数据的手工编辑能力,需要根据数据的格式定义为每一种类型设计编辑器;第二个难点则是跟服务端 API 的对接。
- 模板:与数据之间的连接是数据的格式,对 JSON 格式来说,JSON Schema 是社区接受度较高的一个方案。模板必须是版本化的,必须保持可以回滚。模板设计还有批量更新的需求。
- 模块:模块跟模板非常相似,但是从产品的角度,模块是可组合的。跟模板相似的部分如数据连接、版本化发布、批量更新等。模块化搭建有额外的技术难点,就是可拖拽的模块编辑器。
- 页面:最终生产的目标都是页面。页面同样需要版本化发布,便于回滚。页面部分实现的难点是跟发布系统的结合,就是跟生产环境的对接。
2
3
4
- 搭建系统的实施:搭建系统的实施可以说是所有系统中最容易的了,对多数公司来说搭建系统是一种刚性需求,只要完成了产品开发,立刻会有大量的用户。
- 搭建系统的监控:作为一个工具型技术产品,搭建系统同样会产生大量有价值的数据,搭建系统的用户访问和生产页面数量是衡量自身的重要指标。
# 前端架构:前端架构有哪些核心问题
- 架构是为了分工而存在的。但是到了前端领域,这个问题是否还存在呢?答案是,不存在。【1】前端是个天然按照页面解耦的技术,在多页面架构中,页面的复杂度大约刚好适合一个人的工作量。【2】前端不存在分工问题,但是在多人协同时,仍然要解决质量和效率的问题,这就需要组件化了。除此之外还有前端特有的兼容性问题,也是需要从架构的角度去解决的。【3】对于一些追求极致的团队来说,会挑战 “单页面应用”,通过单页面应用来提升用户体验,单页面应用的升级版本是谷歌提出的 PWA,PWA 既是业务方案也是技术方案,在技术层面,它近乎苛刻地规定了网页的各方面的体验标准。【4】前端领域还有一个特有的生态:框架。
- 组件化:前端主要的开发工作是 UI 开发,而把 UI 上的各种元素分解成组件,规定组件的标准,实现组件运行的环境就是组件化了。现行的组件化方案,目前有五种主流选择:Web Component;Vue;React;Angular;自研。
- 兼容性和适配性:前端开发的特有问题就是兼容性,到了移动时代,面对不同的机型又需要解决适配性问题。
适配问题主要适配的是屏幕的三个要素:
单位英寸像素数(Pixel Per Inch,PPI):现实世界的一英寸内像素数,决定了屏幕的显示质量。
设备像素比率(Device Pixel Ratio,DPR):物理像素与逻辑像素(px)的对应关系。
分辨率(Resolution):屏幕区域的宽高所占像素数。
在当前环境下,分辨率适配可以使用 vw 单位解决,DPR 适配则需要用到 CSS 的 viewport 规则来控制缩放比例解决,而 PPI 主要影响的是文字,可以采用 media 规则来适配。
2
3
4
5
6
- 单页应用:浏览器加载 HTML 时是会有白屏过程的,对追求极致体验的团队来说,希望能够进一步提升体验,于是就有了 “单页应用(SPA)” 的概念。单页应用是把多个页面的内容实现在同一个实际页面内的技术,因为失去了页面的天然解耦,所以就要解决耦合问题。也就是说,要在一个 “物理页面” 内,通过架构设计来实现若干个 “逻辑页面”。
- 扩展前端新边界:前端架构还包含了很多 Native 开发任务:如客户端和前端结合的方案 Weex 和 React Native;如前端和图形学结合的方案 GCanvas;如前端的 3D 框架 Three.js,这些都是试图用架构的手段赋予前端新的能力的尝试。
# 6. 特别加餐
# 新年彩蛋 | 2019,有哪些前端技术值得关注
- 图形学。
- 包管理。
- 智能研发,AI 领域和前端的结合。
# 用户故事 | 那些你与“重学前端”的不解之缘
- 极客时间用户分享:对于框架的使用没必要花太多时间,应该多研究一下三大框架背后的设计思想;当一个程序员对算法、语言标准、底层、原生、英文文档这些词汇产生恐惧感的时候,他的技术生命已经走到尽头;前端架构主要解决的是高复用性,架构能力提升方向主要是组件库开发、前端框架实现等;在自己相对熟悉的领域再去扩展去突破,横向只是拓宽你的眼界,纵向才是你的核心竞争力。
# 期中答疑
- 什么是闭包:闭包其实就是函数,还是能访问外面变量的函数。
- 对象中
name(){}等同于name: function() {},这两个写法有什么区别:这两个写法在使用上基本没什么区别。只有一点区别,就是函数的 name 属性不一样。
var o2 = {
myfunc(){
console.log(myfunc); // error
}
}
var o1 = {
myfunc: function myfunc(){
console.log(myfunc); // function myfunc
}
}
o1.myfunc();
o2.myfunc();
2
3
4
5
6
7
8
9
10
11
12
13
- “词法环境” 和 “词法作用域” 这两个概念的区别是什么:词法环境是运行时概念,词法作用域是语言概念,就是说,作用域指的是变量生效的那段代码,而词法环境是指运行起来之后,你这段代码访问的存储变量的内存块。
- import 进来的引用为什么可以获取到最新的值:涉及了一个叫做 ImportEntry Record 的机制,它比 getter 的实现更底层。
- 微任务是 JavaScript 引擎内部的一种机制,如果不设计微任务,那么 JavaScript 引擎中就完全没有异步。
# 期末答疑
- 前端代码单元测试:一是出一套好的单元测试方案,二是在基础库和框架开发中引入单元测试。
- 大小写的两个属性有什么区别:Screen、screen / Event、event,大写的是类,小写的是对象。
- 函数调用和函数执行有什么区别? 有没有相应的标准?一般讲 “A 函数调用了 B 函数”,“浏览器执行了 B 函数”,所以两者的区别是主语不同。它们对应的标准都是 ECMA262。
- CSSOM 是有 rule 部分和 view 部分的,rule 部分是在 DOM 开始之前就构建完成的,而 view 部分是跟着 DOM 同步构建的。
# 答疑加餐 | 学了这么多前端的“小众”知识,到底对我有什么帮助
- 不要执着于知识的 “临时” 实用性。
# 6. 尾声
# 尾声 | 长风破浪会有时,直挂云帆济沧海
- 教育是知识的展现形式。
- 教育的重点在于能力提升而不是知识积累。
- 教育是一种服务。
